 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatchED: Crisp Edge Detection Using End-to-End, Matching-based Supervision
Feb 24, 2026Generating crisp, i.e., one-pixel-wide, edge maps remains one of the fundamental challenges in edge detection, affecting both traditional and learning-based methods. To obtain crisp edges, most existing approaches rely on two hand-crafted post-processing algorithms, Non-Maximum Suppression (NMS) and skeleton-based thinning, which are non-differentiable and hinder end-to-end optimization. Moreover, all existing crisp edge detection methods still depend on such post-processing to achieve satisfactory results. To address this limitation, we propose \MethodLPP, a lightweight, only $\sim$21K additional parameters, and plug-and-play matching-based supervision module that can be appended to any edge detection model for joint end-to-end learning of crisp edges. At each training iteration, \MethodLPP performs one-to-one matching between predicted and ground-truth edges based on spatial distance and confidence, ensuring consistency between training and testing protocols. Extensive experiments on four popular datasets demonstrate that integrating \MethodLPP substantially improves the performance of existing edge detection models. In particular, \MethodLPP increases the Average Crispness (AC) metric by up to 2--4$\times$ compared to baseline models. Under the crispness-emphasized evaluation (CEval), \MethodLPP further boosts baseline performance by up to 20--35\% in ODS and achieves similar gains in OIS and AP, achieving SOTA performance that matches or surpasses standard post-processing for the first time. Code is available at https://cvpr26-matched.github.io.
RSPose: Ranking Based Losses for Human Pose Estimation
Nov 17, 2025While heatmap-based human pose estimation methods have shown strong performance, they suffer from three main problems: (P1) "Commonly used Mean Squared Error (MSE)" Loss may not always improve joint localization because it penalizes all pixel deviations equally, without focusing explicitly on sharpening and correctly localizing the peak corresponding to the joint; (P2) heatmaps are spatially and class-wise imbalanced; and, (P3) there is a discrepancy between the evaluation metric (i.e., mAP) and the loss functions. We propose ranking-based losses to address these issues. Both theoretically and empirically, we show that our proposed losses are superior to commonly used heatmap losses (MSE, KL-Divergence). Our losses considerably increase the correlation between confidence scores and localization qualities, which is desirable because higher correlation leads to more accurate instance selection during Non-Maximum Suppression (NMS) and better Average Precision (mAP) performance. We refer to the models trained with our losses as RSPose. We show the effectiveness of RSPose across two different modes: one-dimensional and two-dimensional heatmaps, on three different datasets (COCO, CrowdPose, MPII). To the best of our knowledge, we are the first to propose losses that align with the evaluation metric (mAP) for human pose estimation. RSPose outperforms the previous state of the art on the COCO-val set and achieves an mAP score of 79.9 with ViTPose-H, a vision transformer model for human pose estimation. We also improve SimCC Resnet-50, a coordinate classification-based pose estimation method, by 1.5 AP on the COCO-val set, achieving 73.6 AP.
RankED: Addressing Imbalance and Uncertainty in Edge Detection Using Ranking-based Losses
Mar 07, 2024Detecting edges in images suffers from the problems of (P1) heavy imbalance between positive and negative classes as well as (P2) label uncertainty owing to disagreement between different annotators. Existing solutions address P1 using class-balanced cross-entropy loss and dice loss and P2 by only predicting edges agreed upon by most annotators. In this paper, we propose RankED, a unified ranking-based approach that addresses both the imbalance problem (P1) and the uncertainty problem (P2). RankED tackles these two problems with two components: One component which ranks positive pixels over negative pixels, and the second which promotes high confidence edge pixels to have more label certainty. We show that RankED outperforms previous studies and sets a new state-of-the-art on NYUD-v2, BSDS500 and Multi-cue datasets. Code is available at https://ranked-cvpr24.github.io.
A New Multi-Level Hazy Image and Video Dataset for Benchmark of Dehazing Methods
Jul 29, 2023The changing level of haze is one of the main factors which affects the success of the proposed dehazing methods. However, there is a lack of controlled multi-level hazy dataset in the literature. Therefore, in this study, a new multi-level hazy color image dataset is presented. Color video data is captured for two real scenes with a controlled level of haze. The distance of the scene objects from the camera, haze level, and ground truth (clear image) are available so that different dehazing methods and models can be benchmarked. In this study, the dehazing performance of five different dehazing methods/models is compared on the dataset based on SSIM, PSNR, VSI and DISTS image quality metrics. Results show that traditional methods can generalize the dehazing problem better than many deep learning based methods. The performance of deep models depends mostly on the scene and is generally poor on cross-dataset dehazing.
Does depth estimation help object detection?
Apr 13, 2022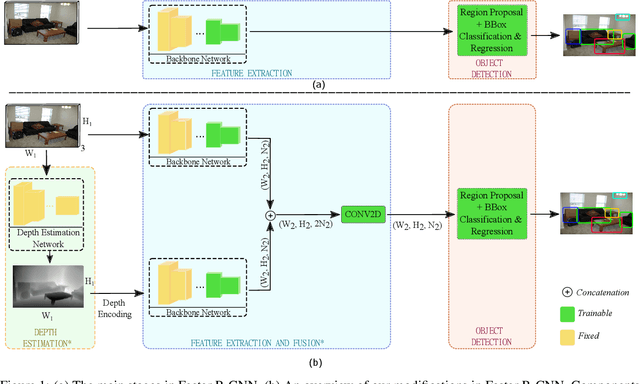

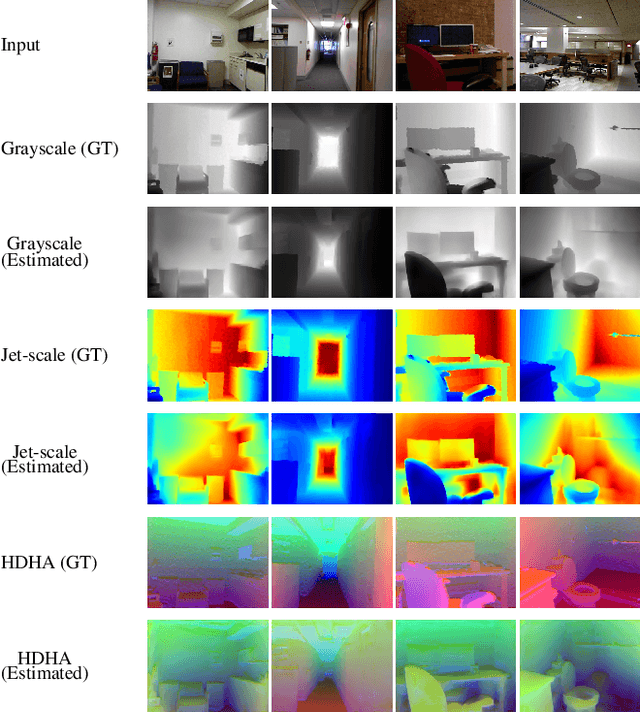
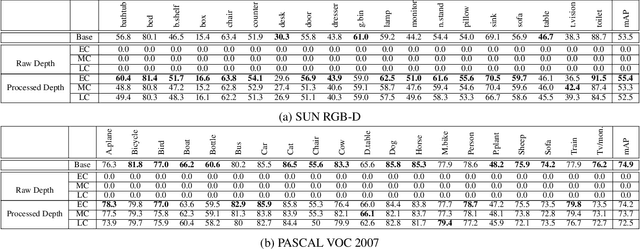
Ground-truth depth, when combined with color data, helps improve object detection accuracy over baseline models that only use color. However, estimated depth does not always yield improvements. Many factors affect the performance of object detection when estimated depth is used. In this paper, we comprehensively investigate these factors with detailed experiments, such as using ground-truth vs. estimated depth, effects of different state-of-the-art depth estimation networks, effects of using different indoor and outdoor RGB-D datasets as training data for depth estimation, and different architectural choices for integrating depth to the base object detector network. We propose an early concatenation strategy of depth, which yields higher mAP than previous works' while using significantly fewer parameters.