 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes depth estimation help object detection?
Paper and Code
Apr 13, 2022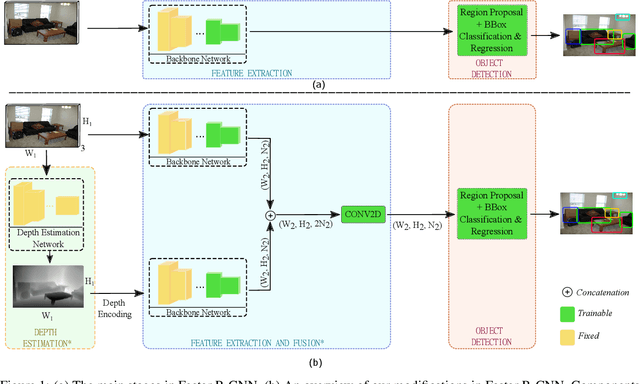

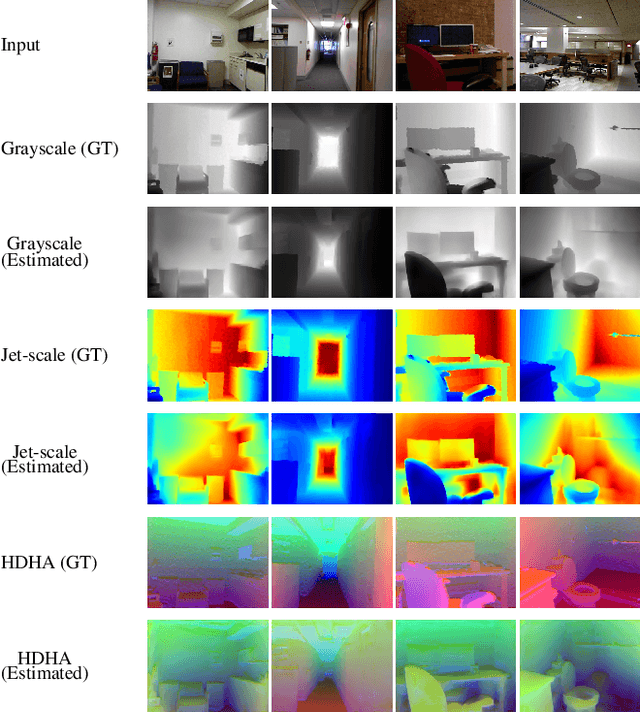
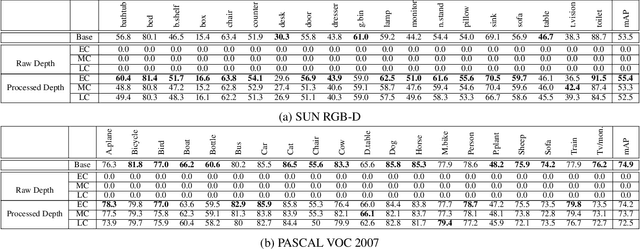
Ground-truth depth, when combined with color data, helps improve object detection accuracy over baseline models that only use color. However, estimated depth does not always yield improvements. Many factors affect the performance of object detection when estimated depth is used. In this paper, we comprehensively investigate these factors with detailed experiments, such as using ground-truth vs. estimated depth, effects of different state-of-the-art depth estimation networks, effects of using different indoor and outdoor RGB-D datasets as training data for depth estimation, and different architectural choices for integrating depth to the base object detector network. We propose an early concatenation strategy of depth, which yields higher mAP than previous works' while using significantly fewer parameters.