 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearest Neighbour Few-Shot Learning for Cross-lingual Classification
Sep 06, 2021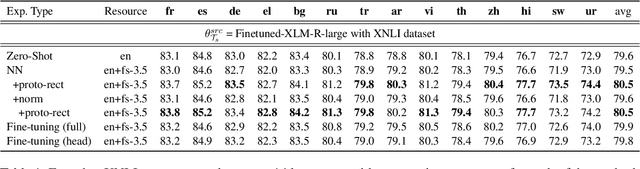
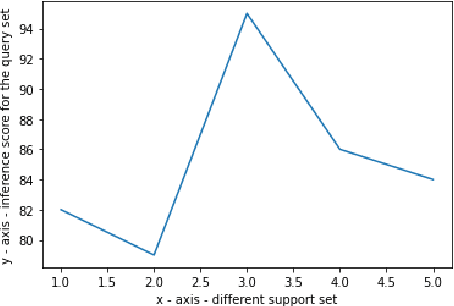
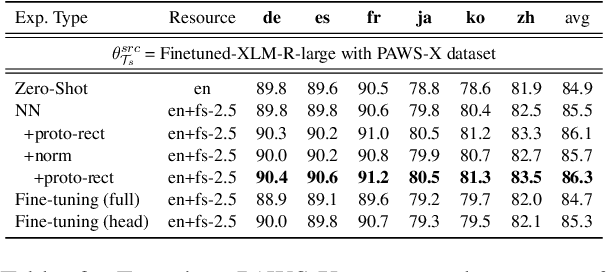
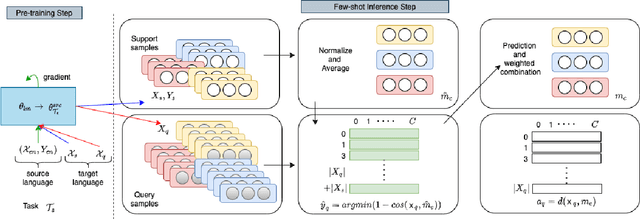
Even though large pre-trained multilingual models (e.g. mBERT, XLM-R) have led to significant performance gains on a wide range of cross-lingual NLP tasks, success on many downstream tasks still relies on the availability of sufficient annotated data. Traditional fine-tuning of pre-trained models using only a few target samples can cause over-fitting. This can be quite limiting as most languages in the world are under-resourced. In this work, we investigate cross-lingual adaptation using a simple nearest neighbor few-shot (<15 samples) inference technique for classification tasks. We experiment using a total of 16 distinct languages across two NLP tasks- XNLI and PAWS-X. Our approach consistently improves traditional fine-tuning using only a handful of labeled samples in target locales. We also demonstrate its generalization capability across tasks.
Soft Layer Selection with Meta-Learning for Zero-Shot Cross-Lingual Transfer
Jul 21, 2021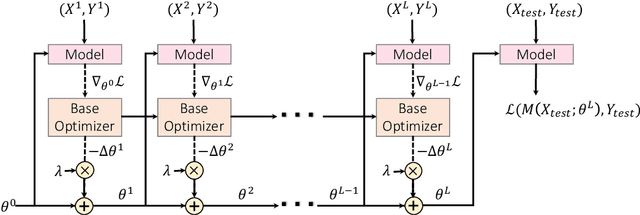
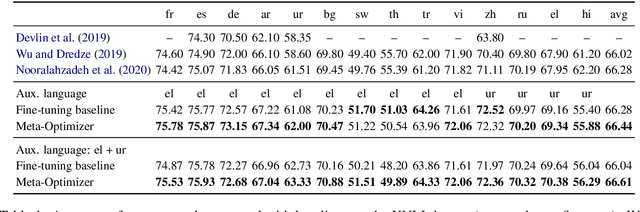

Multilingual pre-trained contextual embedding models (Devlin et al., 2019) have achieved impressive performance on zero-shot cross-lingual transfer tasks. Finding the most effective fine-tuning strategy to fine-tune these models on high-resource languages so that it transfers well to the zero-shot languages is a non-trivial task. In this paper, we propose a novel meta-optimizer to soft-select which layers of the pre-trained model to freeze during fine-tuning. We train the meta-optimizer by simulating the zero-shot transfer scenario. Results on cross-lingual natural language inference show that our approach improves over the simple fine-tuning baseline and X-MAML (Nooralahzadeh et al., 2020).
End-to-End Slot Alignment and Recognition for Cross-Lingual NLU
Apr 29, 2020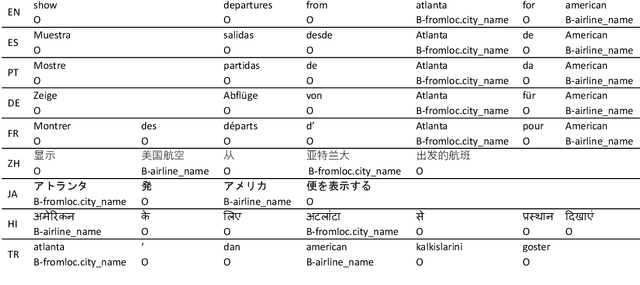
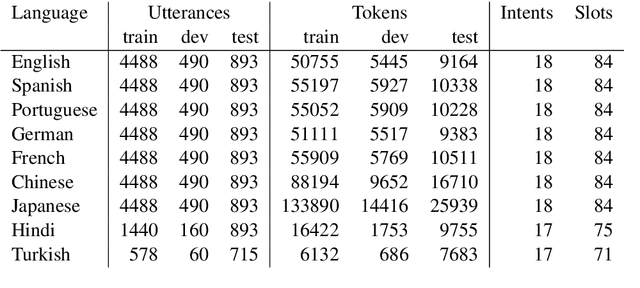
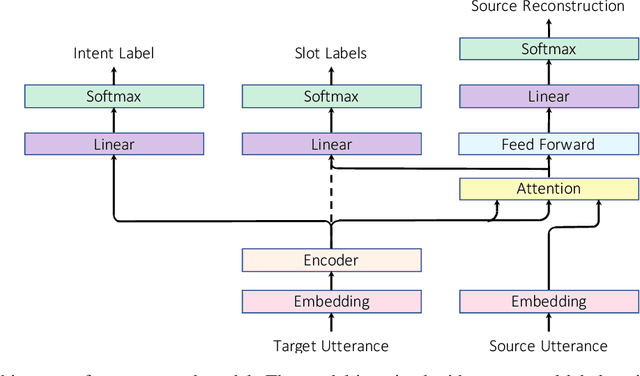
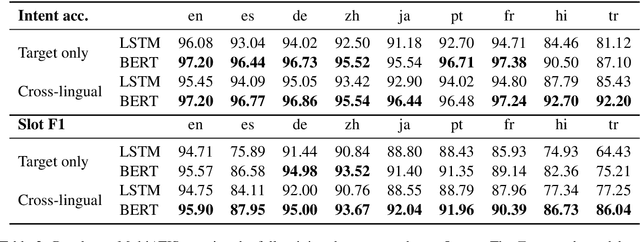
Natural language understanding in the context of goal oriented dialog systems typically includes intent classification and slot labeling tasks. An effective method to expand an NLU system to new languages is using machine translation (MT) with annotation projection to the target language. Previous work focused on using word alignment tools or complex heuristics for slot annotation projection. In this work, we propose a novel end-to-end model that learns to align and predict slots. Existing multilingual NLU data sets only support up to three languages which limits the study on cross-lingual transfer. To this end, we construct a multilingual NLU corpus, MultiATIS++, by extending the Multilingual ATIS corpus to nine languages across various language families. We use the corpus to explore various cross-lingual transfer methods focusing on the zero-shot setting and leveraging MT for language expansion. Results show that our soft-alignment method significantly improves slot F1 over strong baselines on most languages. In addition, our experiments show the strength of using multilingual BERT for both cross-lingual training and zero-shot transfer.