 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementation and Comparison of Methods to Extract Reliability KPIs out of Textual Wind Turbine Maintenance Work Orders
Nov 07, 2023Maintenance work orders are commonly used to document information about wind turbine operation and maintenance. This includes details about proactive and reactive wind turbine downtimes, such as preventative and corrective maintenance. However, the information contained in maintenance work orders is often unstructured and difficult to analyze, making it challenging for decision-makers to use this information for optimizing operation and maintenance. To address this issue, this work presents three different approaches to calculate reliability key performance indicators from maintenance work orders. The first approach involves manual labeling of the maintenance work orders by domain experts, using the schema defined in an industrial guideline to assign the label accordingly. The second approach involves the development of a model that automatically labels the maintenance work orders using text classification methods. The third technique uses an AI-assisted tagging tool to tag and structure the raw maintenance information contained in the maintenance work orders. The resulting calculated reliability key performance indicator of the first approach are used as a benchmark for comparison with the results of the second and third approaches. The quality and time spent are considered as criteria for evaluation. Overall, these three methods make extracting maintenance information from maintenance work orders more efficient, enable the assessment of reliability key performance indicators and therefore support the optimization of wind turbine operation and maintenance.
Research Topic Flows in Co-Authorship Networks
Jun 16, 2022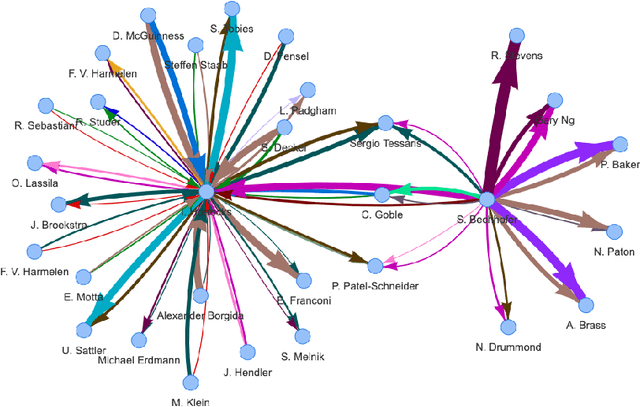

In scientometrics, scientific collaboration is often analyzed by means of co-authorships. An aspect which is often overlooked and more difficult to quantify is the flow of expertise between authors from different research topics, which is an important part of scientific progress. With the Topic Flow Network (TFN) we propose a graph structure for the analysis of research topic flows between scientific authors and their respective research fields. Based on a multi-graph and a topic model, our proposed network structure accounts for intratopic as well as intertopic flows. Our method requires for the construction of a TFN solely a corpus of publications (i.e., author and abstract information). From this, research topics are discovered automatically through non-negative matrix factorization. The thereof derived TFN allows for the application of social network analysis techniques, such as common metrics and community detection. Most importantly, it allows for the analysis of intertopic flows on a large, macroscopic scale, i.e., between research topic, as well as on a microscopic scale, i.e., between certain sets of authors. We demonstrate the utility of TFNs by applying our method to two comprehensive corpora of altogether 20 Mio. publications spanning more than 60 years of research in the fields computer science and mathematics. Our results give evidence that TFNs are suitable, e.g., for the analysis of topical communities, the discovery of important authors in different fields, and, most notably, the analysis of intertopic flows, i.e., the transfer of topical expertise. Besides that, our method opens new directions for future research, such as the investigation of influence relationships between research fields.
Mapping Research Trajectories
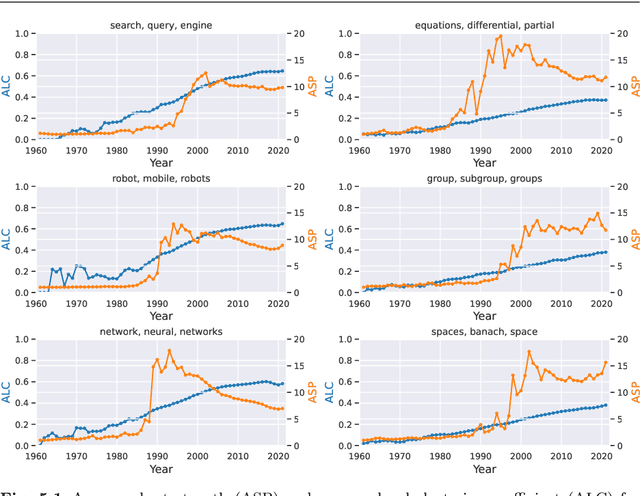
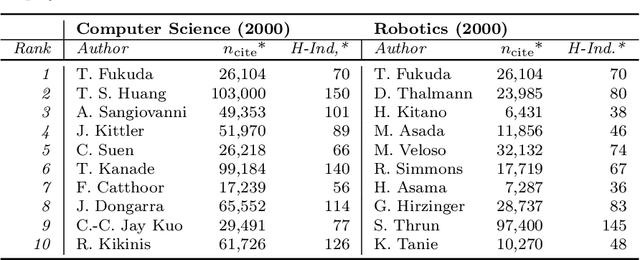
Apr 25, 2022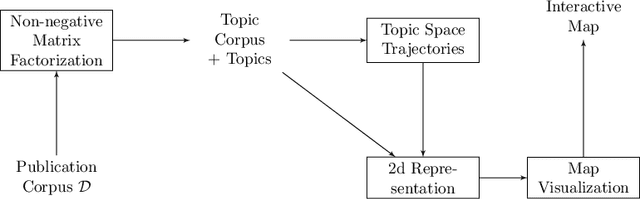
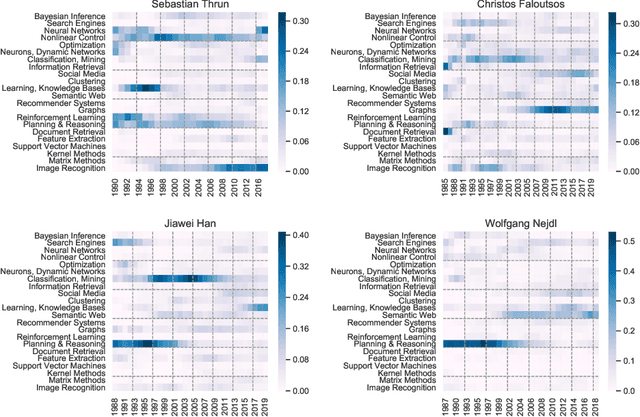
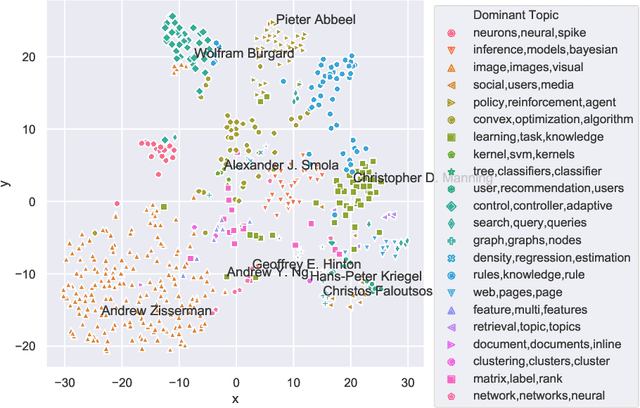
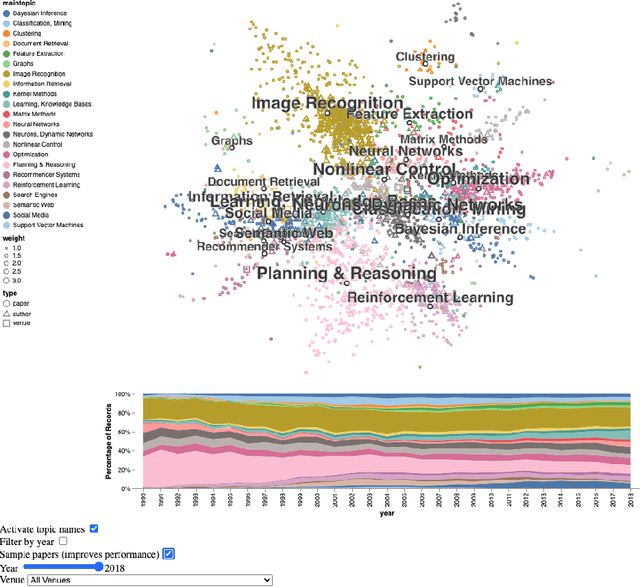
Steadily growing amounts of information, such as annually published scientific papers, have become so large that they elude an extensive manual analysis. Hence, to maintain an overview, automated methods for the mapping and visualization of knowledge domains are necessary and important, e.g., for scientific decision makers. Of particular interest in this field is the development of research topics of different entities (e.g., scientific authors and venues) over time. However, existing approaches for their analysis are only suitable for single entity types, such as venues, and they often do not capture the research topics or the time dimension in an easily interpretable manner. Hence, we propose a principled approach for \emph{mapping research trajectories}, which is applicable to all kinds of scientific entities that can be represented by sets of published papers. For this, we transfer ideas and principles from the geographic visualization domain, specifically trajectory maps and interactive geographic maps. Our visualizations depict the research topics of entities over time in a straightforward interpr. manner. They can be navigated by the user intuitively and restricted to specific elements of interest. The maps are derived from a corpus of research publications (i.e., titles and abstracts) through a combination of unsupervised machine learning methods. In a practical demonstrator application, we exemplify the proposed approach on a publication corpus from machine learning. We observe that our trajectory visualizations of 30 top machine learning venues and 1000 major authors in this field are well interpretable and are consistent with background knowledge drawn from the entities' publications. Next to producing interactive, interpr. visualizations supporting different kinds of analyses, our computed trajectories are suitable for trajectory mining applications in the future.
Towards Explainable Scientific Venue Recommendations
Sep 21, 2021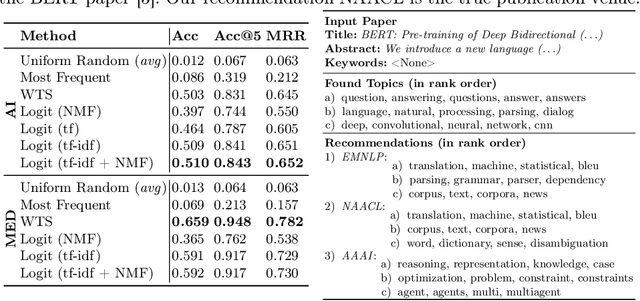
Selecting the best scientific venue (i.e., conference/journal) for the submission of a research article constitutes a multifaceted challenge. Important aspects to consider are the suitability of research topics, a venue's prestige, and the probability of acceptance. The selection problem is exacerbated through the continuous emergence of additional venues. Previously proposed approaches for supporting authors in this process rely on complex recommender systems, e.g., based on Word2Vec or TextCNN. These, however, often elude an explanation for their recommendations. In this work, we propose an unsophisticated method that advances the state-of-the-art in two aspects: First, we enhance the interpretability of recommendations through non-negative matrix factorization based topic models; Second, we surprisingly can obtain competitive recommendation performance while using simpler learning methods.
Topic Space Trajectories: A case study on machine learning literature
Oct 26, 2020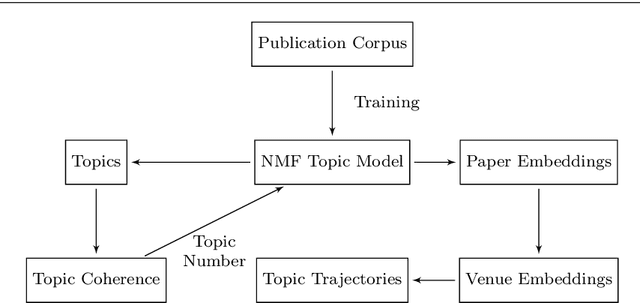
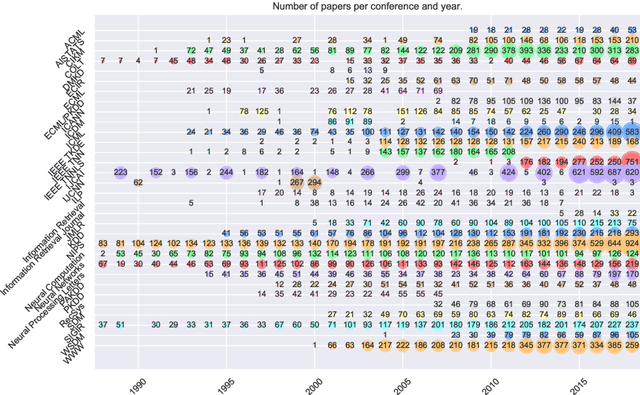
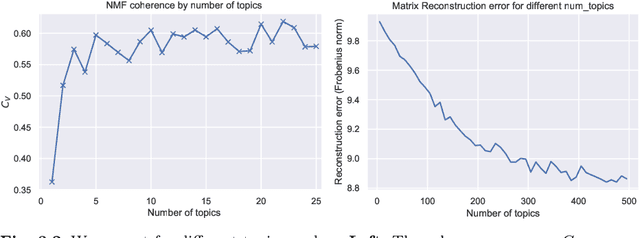
The annual number of publications at scientific venues, for example, conferences and journals, is growing quickly. Hence, even for researchers it becomes harder and harder to keep track of research topics and their progress. In this task, researchers can be supported by automated publication analysis. Yet, many such methods result in uninterpretable, purely numerical representations. As an attempt to support human analysts, we present \emph{topic space trajectories}, a structure that allows for the comprehensible tracking of research topics. We demonstrate how these trajectories can be interpreted based on eight different analysis approaches. To obtain comprehensible results, we employ non-negative matrix factorization as well as suitable visualization techniques. We show the applicability of our approach on a publication corpus spanning 50 years of machine learning research from 32 publication venues. Our novel analysis method may be employed for paper classification, for the prediction of future research topics, and for the recommendation of fitting conferences and journals for submitting unpublished work.
Distances for WiFi Based Topological Indoor Mapping
Sep 19, 2018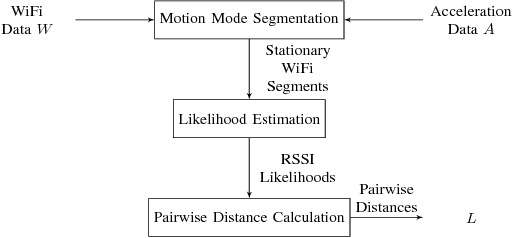
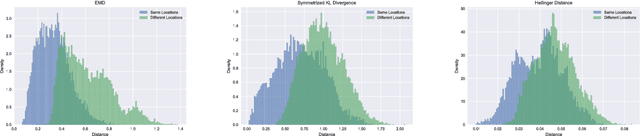
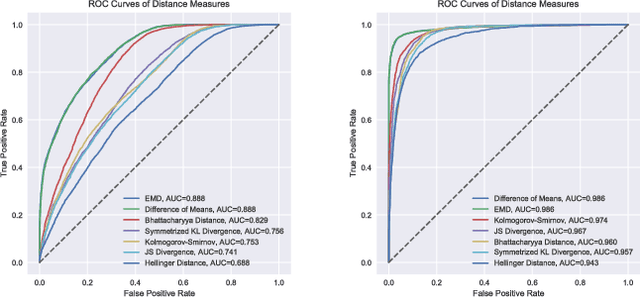
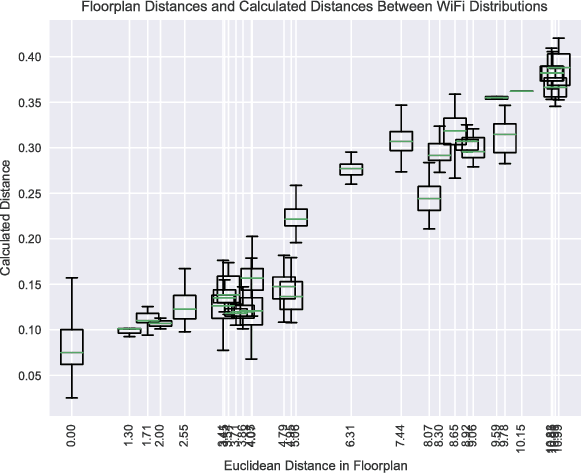
For localization and mapping of indoor environments through WiFi signals, locations are often represented as likelihoods of the received signal strength indicator. In this work we compare various measures of distance between such likelihoods in combination with different methods for estimation and representation. In particular, we show that among the considered distance measures the Earth Mover's Distance seems the most beneficial for the localization task. Combined with kernel density estimation we were able to retain the topological structure of rooms in a real-world office scenario.