 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the Arabic Sentiment Analysis 2021 Competition at KAUST
Sep 29, 2021


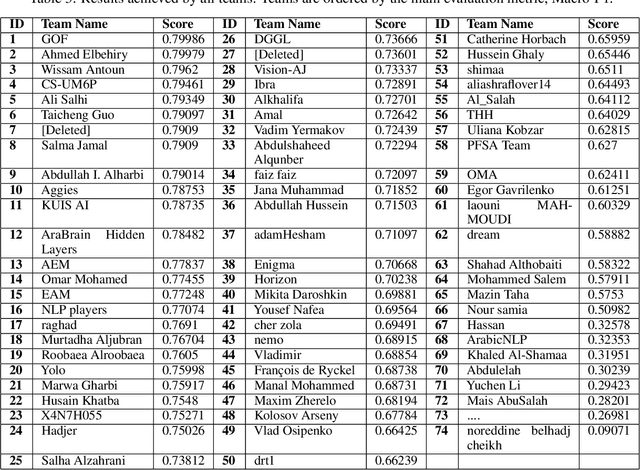
This paper provides an overview of the Arabic Sentiment Analysis Challenge organized by King Abdullah University of Science and Technology (KAUST). The task in this challenge is to develop machine learning models to classify a given tweet into one of the three categories Positive, Negative, or Neutral. From our recently released ASAD dataset, we provide the competitors with 55K tweets for training, and 20K tweets for validation, based on which the performance of participating teams are ranked on a leaderboard, https://www.kaggle.com/c/arabic-sentiment-analysis-2021-kaust. The competition received in total 1247 submissions from 74 teams (99 team members). The final winners are determined by another private set of 20K tweets that have the same distribution as the training and validation set. In this paper, we present the main findings in the competition and summarize the methods and tools used by the top ranked teams. The full dataset of 100K labeled tweets is also released for public usage, at https://www.kaggle.com/c/arabic-sentiment-analysis-2021-kaust/data.
ASAD: A Twitter-based Benchmark Arabic Sentiment Analysis Dataset
Nov 01, 2020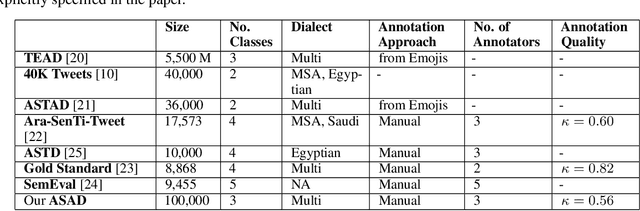


This paper provides a detailed description of a new Twitter-based benchmark dataset for Arabic Sentiment Analysis (ASAD), which is launched in a competition3, sponsored by KAUST for awarding 10000 USD, 5000 USD and 2000 USD to the first, second and third place winners, respectively. Compared to other publicly released Arabic datasets, ASAD is a large, high-quality annotated dataset(including 95K tweets), with three-class sentiment labels (positive, negative and neutral). We presents the details of the data collection process and annotation process. In addition, we implement several baseline models for the competition task and report the results as a reference for the participants to the competition.