 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Guided Prefiltering for VLM Image Compression
Mar 31, 2026The rapid progress of large Vision-Language Models (VLMs) has enabled a wide range of applications, such as image understanding and Visual Question Answering (VQA). Query images are often uploaded to the cloud, where VLMs are typically hosted, hence efficient image compression becomes crucial. However, traditional human-centric codecs are suboptimal in this setting because they preserve many task-irrelevant details. Existing Image Coding for Machines (ICM) methods also fall short, as they assume a fixed set of downstream tasks and cannot adapt to prompt-driven VLMs with an open-ended variety of objectives. We propose a lightweight, plug-and-play, prompt-guided prefiltering module to identify image regions most relevant to the text prompt, and consequently to the downstream task. The module preserves important details while smoothing out less relevant areas to improve compression efficiency. It is codec-agnostic and can be applied before conventional and learned encoders. Experiments on several VQA benchmarks show that our approach achieves a 25-50% average bitrate reduction while maintaining the same task accuracy. Our source code is available at https://github.com/bardia-az/pgp-vlm-compression.
Privacy-Preserving Autoencoder for Collaborative Object Detection
Feb 29, 2024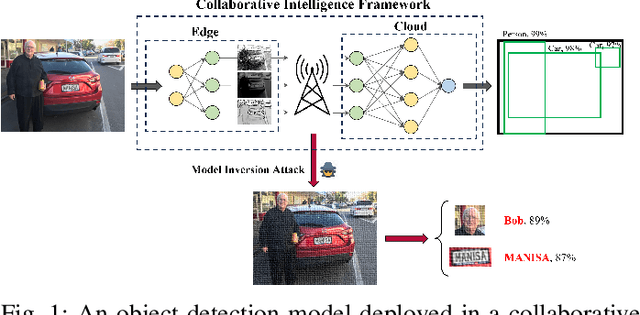
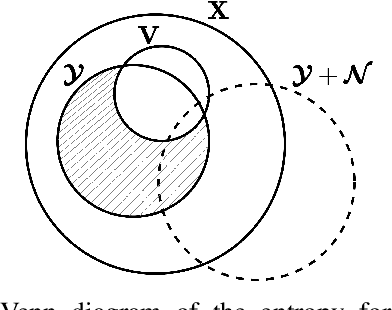
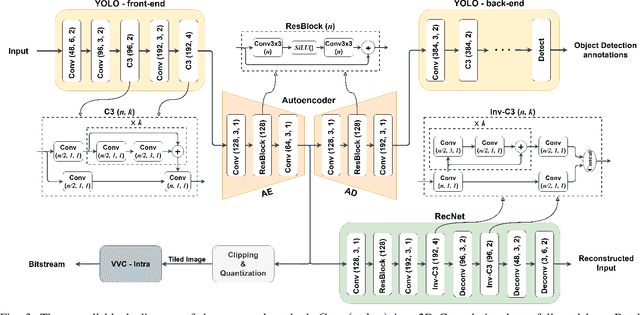

Privacy is a crucial concern in collaborative machine vision where a part of a Deep Neural Network (DNN) model runs on the edge, and the rest is executed on the cloud. In such applications, the machine vision model does not need the exact visual content to perform its task. Taking advantage of this potential, private information could be removed from the data insofar as it does not significantly impair the accuracy of the machine vision system. In this paper, we present an autoencoder-style network integrated within an object detection pipeline, which generates a latent representation of the input image that preserves task-relevant information while removing private information. Our approach employs an adversarial training strategy that not only removes private information from the bottleneck of the autoencoder but also promotes improved compression efficiency for feature channels coded by conventional codecs like VVC-Intra. We assess the proposed system using a realistic evaluation framework for privacy, directly measuring face and license plate recognition accuracy. Experimental results show that our proposed method is able to reduce the bitrate significantly at the same object detection accuracy compared to coding the input images directly, while keeping the face and license plate recognition accuracy on the images recovered from the bottleneck features low, implying strong privacy protection.
Privacy-Preserving Feature Coding for Machines
Oct 03, 2022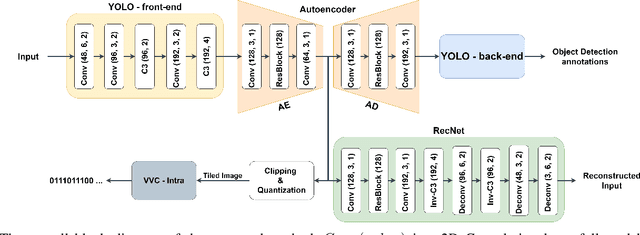
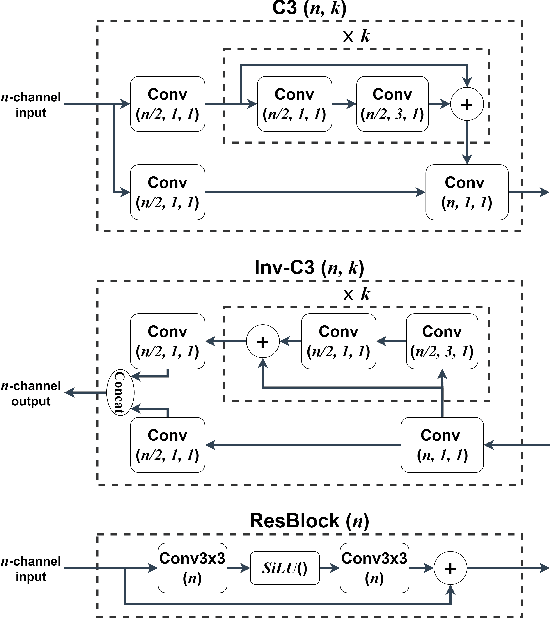

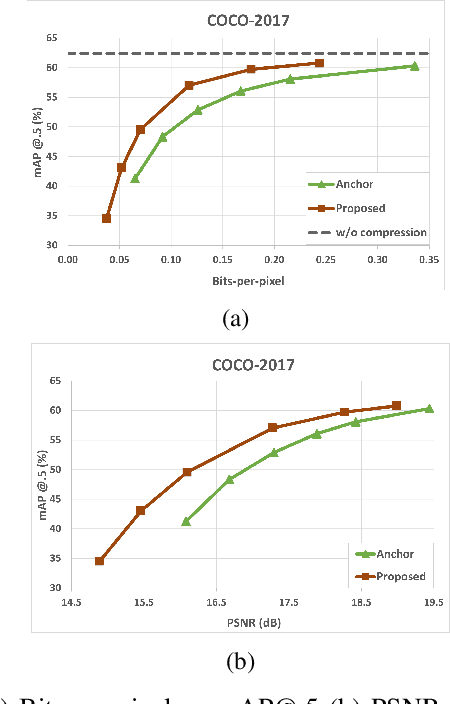
Automated machine vision pipelines do not need the exact visual content to perform their tasks. Therefore, there is a potential to remove private information from the data without significantly affecting the machine vision accuracy. We present a novel method to create a privacy-preserving latent representation of an image that could be used by a downstream machine vision model. This latent representation is constructed using adversarial training to prevent accurate reconstruction of the input while preserving the task accuracy. Specifically, we split a Deep Neural Network (DNN) model and insert an autoencoder whose purpose is to both reduce the dimensionality as well as remove information relevant to input reconstruction while minimizing the impact on task accuracy. Our results show that input reconstruction ability can be reduced by about 0.8 dB at the equivalent task accuracy, with degradation concentrated near the edges, which is important for privacy. At the same time, 30% bit savings are achieved compared to coding the features directly.