 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Multilingual Text Embedding Rankings Across Learning Tasks, Languages, and Benchmark Datasets
May 29, 2026Large-scale multilingual text embedding models play crucial role in both research and industry, yet their behavior in language-specific, multi-task settings remains insufficiently understood. Although benchmarking platforms such as MTEB report results across more than 250 languages, conclusions about model superiority often depend on implicit choices of dataset compositions and performance aggregation methods. To address this gap, we present a meta-study of multilingual model performance robustness in MTEB, applying a diverse set of multi-criteria decision-making ranking schemes and introducing two robustness indicators: dataset-composition robustness (sensitivity of rankings to changing dataset compositions) and ranking-scheme robustness (sensitivity to aggregation method change). They enable systematic sensitivity analysis of whether benchmarking conclusions remain stable under different evaluation designs. We conduct an in-depth analysis on five languages (English, French, German, Hindi, and Spanish) across nine tasks (e.g., classification, clustering, retrieval) and release results for approximately 230 additional languages. The task-specific analyses show that large-scale LLM-based models are often robust top performers, though not uniformly (e.g., in retrieval task), while task-agnostic results reveal that only a small subset of models remains consistently strong across tasks, ranking schemes, and data subsamples.
On the Structural (Dis)Agreement of Landscape Representations in Black-Box Optimization
May 27, 2026Landscape feature representations play a central role in automated algorithm selection and meta-learning for black-box optimization, yet little is known about how different representations agree (or disagree) in the structures they impose on problem spaces. This paper presents a systematic unsupervised evaluation of four state-of-the-art representations (ELA, DeepELA, TransOptAS, and DoE2Vec) using a diverse set of affine combinations of BBOB functions (MA-BBOB). By applying extensive clustering analyses, coverage-based stability measures, and cross-representation similarity assessments, we show that each representation organizes the same problems in markedly different ways: ELA and TransOptAS form compact geometric structures, DeepELA provides a balanced intermediate view, and DoE2Vec achieves strong semantic alignment but with substantial fragmentation. Our results reveal that no single representation dominates; rather, they capture complementary aspects of the underlying landscapes. These findings highlight the importance of multi-view analyses for understanding representation behavior and offer guidance on selecting or combining representations in downstream meta-learning and algorithm selection tasks. In addition, across two different algorithm families (Differential Evolution and Particle Swarm Optimization), we show that landscape representations face an inherent trade-off in how well they align structural landscape descriptions with observed performance, indicating that no single representation can fully capture algorithm performance.
Evaluation of LLMs in retrieving food and nutritional context for RAG systems
Mar 11, 2026In this article, we evaluate four Large Language Models (LLMs) and their effectiveness at retrieving data within a specialized Retrieval-Augmented Generation (RAG) system, using a comprehensive food composition database. Our method is focused on the LLMs ability to translate natural language queries into structured metadata filters, enabling efficient retrieval via a Chroma vector database. By achieving high accuracy in this critical retrieval step, we demonstrate that LLMs can serve as an accessible, high-performance tool, drastically reducing the manual effort and technical expertise previously required for domain experts, such as food compilers and nutritionists, to leverage complex food and nutrition data. However, despite the high performance on easy and moderately complex queries, our analysis of difficult questions reveals that reliable retrieval remains challenging when queries involve non-expressible constraints. These findings demonstrate that LLM-driven metadata filtering excels when constraints can be explicitly expressed, but struggles when queries exceed the representational scope of the metadata format.
FoodSEM: Large Language Model Specialized in Food Named-Entity Linking
Sep 26, 2025This paper introduces FoodSEM, a state-of-the-art fine-tuned open-source large language model (LLM) for named-entity linking (NEL) to food-related ontologies. To the best of our knowledge, food NEL is a task that cannot be accurately solved by state-of-the-art general-purpose (large) language models or custom domain-specific models/systems. Through an instruction-response (IR) scenario, FoodSEM links food-related entities mentioned in a text to several ontologies, including FoodOn, SNOMED-CT, and the Hansard taxonomy. The FoodSEM model achieves state-of-the-art performance compared to related models/systems, with F1 scores even reaching 98% on some ontologies and datasets. The presented comparative analyses against zero-shot, one-shot, and few-shot LLM prompting baselines further highlight FoodSEM's superior performance over its non-fine-tuned version. By making FoodSEM and its related resources publicly available, the main contributions of this article include (1) publishing a food-annotated corpora into an IR format suitable for LLM fine-tuning/evaluation, (2) publishing a robust model to advance the semantic understanding of text in the food domain, and (3) providing a strong baseline on food NEL for future benchmarking.
Predefined domain specific embeddings of food concepts and recipes: A case study on heterogeneous recipe datasets
Feb 02, 2023Although recipe data are very easy to come by nowadays, it is really hard to find a complete recipe dataset - with a list of ingredients, nutrient values per ingredient, and per recipe, allergens, etc. Recipe datasets are usually collected from social media websites where users post and publish recipes. Usually written with little to no structure, using both standardized and non-standardized units of measurement. We collect six different recipe datasets, publicly available, in different formats, and some including data in different languages. Bringing all of these datasets to the needed format for applying a machine learning (ML) pipeline for nutrient prediction [1], [2], includes data normalization using dictionary-based named entity recognition (NER), rule-based NER, as well as conversions using external domain-specific resources. From the list of ingredients, domain-specific embeddings are created using the same embedding space for all recipes - one ingredient dataset is generated. The result from this normalization process is two corpora - one with predefined ingredient embeddings and one with predefined recipe embeddings. On all six recipe datasets, the ML pipeline is evaluated. The results from this use case also confirm that the embeddings merged using the domain heuristic yield better results than the baselines.
FoodChem: A food-chemical relation extraction model
Oct 08, 2021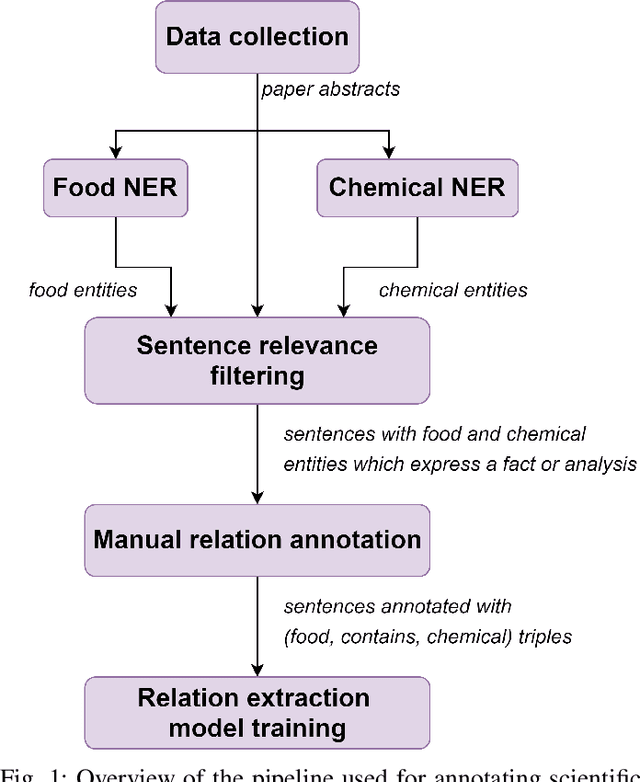
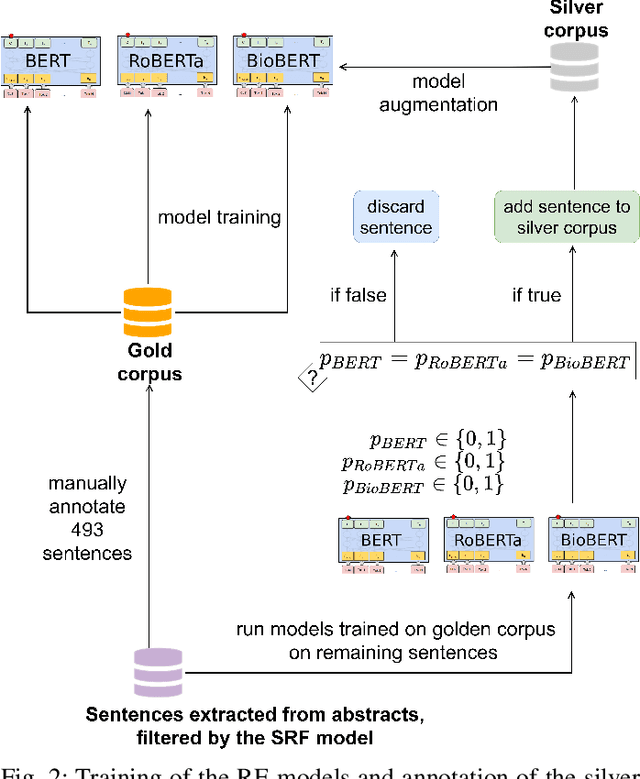
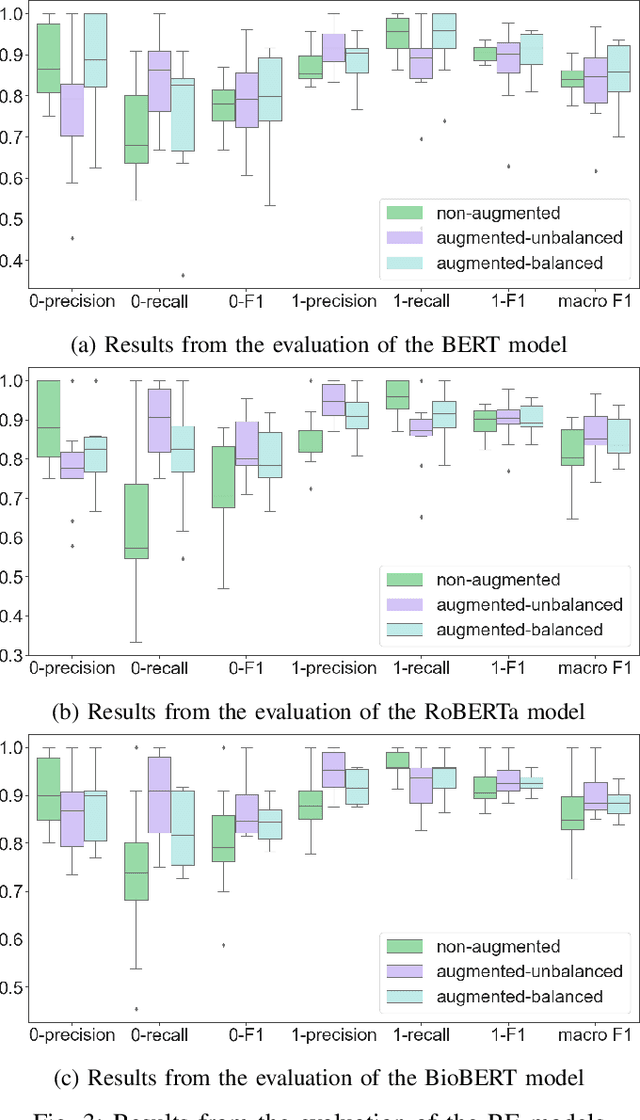
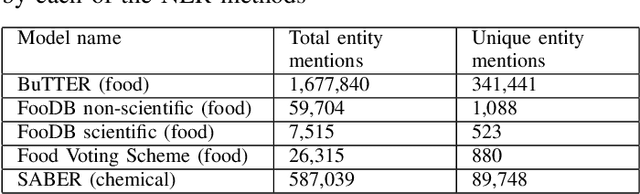
In this paper, we present FoodChem, a new Relation Extraction (RE) model for identifying chemicals present in the composition of food entities, based on textual information provided in biomedical peer-reviewed scientific literature. The RE task is treated as a binary classification problem, aimed at identifying whether the contains relation exists between a food-chemical entity pair. This is accomplished by fine-tuning BERT, BioBERT and RoBERTa transformer models. For evaluation purposes, a novel dataset with annotated contains relations in food-chemical entity pairs is generated, in a golden and silver version. The models are integrated into a voting scheme in order to produce the silver version of the dataset which we use for augmenting the individual models, while the manually annotated golden version is used for their evaluation. Out of the three evaluated models, the BioBERT model achieves the best results, with a macro averaged F1 score of 0.902 in the unbalanced augmentation setting.