 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new sampling methodology for creating rich, heterogeneous, subsets of samples for training image segmentation algorithms
Jan 11, 2023



Creating a dataset for training supervised machine learning algorithms can be a demanding task. This is especially true for medical image segmentation since this task usually requires one or more specialists for image annotation, and creating ground truth labels for just a single image can take up to several hours. In addition, it is paramount that the annotated samples represent well the different conditions that might affect the imaged tissue as well as possible changes in the image acquisition process. This can only be achieved by considering samples that are typical in the dataset as well as atypical, or even outlier, samples. We introduce a new sampling methodology for selecting relevant images from a larger non-annotated dataset in a way that evenly considers both prototypical as well as atypical samples. The methodology involves the generation of a uniform grid from a feature space representing the samples, which is then used for randomly drawing relevant images. The selected images provide a uniform cover of the original dataset, and thus define a heterogeneous set of images that can be annotated and used for training supervised segmentation algorithms. We provide a case example by creating a dataset containing a representative set of blood vessel microscopy images selected from a larger dataset containing thousands of images.
An Analysis of the Influence of Transfer Learning When Measuring the Tortuosity of Blood Vessels
Nov 19, 2021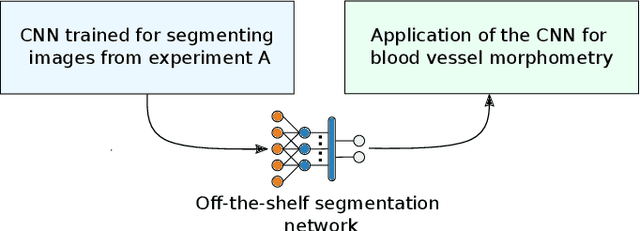
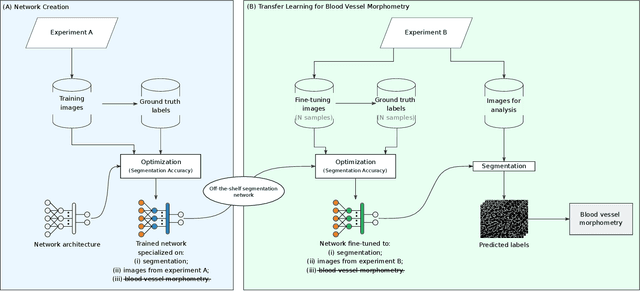
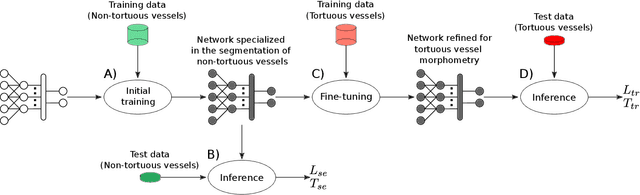
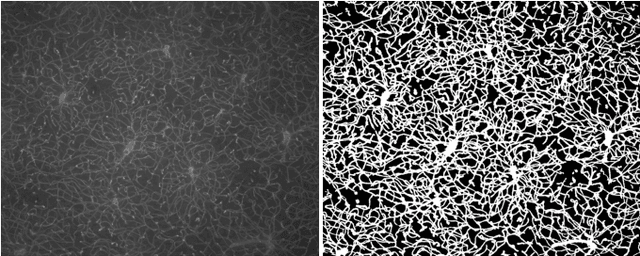
Characterizing blood vessels in digital images is important for the diagnosis of many types of diseases as well as for assisting current researches regarding vascular systems. The automated analysis of blood vessels typically requires the identification, or segmentation, of the blood vessels in an image or a set of images, which is usually a challenging task. Convolutional Neural Networks (CNNs) have been shown to provide excellent results regarding the segmentation of blood vessels. One important aspect of CNNs is that they can be trained on large amounts of data and then be made available, for instance, in image processing software for wide use. The pre-trained CNNs can then be easily applied in downstream blood vessel characterization tasks such as the calculation of the length, tortuosity, or caliber of the blood vessels. Yet, it is still unclear if pre-trained CNNs can provide robust, unbiased, results on downstream tasks when applied to datasets that they were not trained on. Here, we focus on measuring the tortuosity of blood vessels and investigate to which extent CNNs may provide biased tortuosity values even after fine-tuning the network to the new dataset under study. We show that the tortuosity values obtained by a CNN trained from scratch on a dataset may not agree with those obtained by a fine-tuned network that was pre-trained on a dataset having different tortuosity statistics. In addition, we show that the improvement in segmentation performance when fine-tuning the network does not necessarily lead to a respective improvement on the estimation of the tortuosity. To mitigate the aforementioned issues, we propose the application of specific data augmentation techniques even in situations where they do not improve segmentation performance.