 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaipan: A Query-free Transfer-based Multiple Sensitive Attribute Inference Attack Solely from Publicly Released Graphs
Feb 06, 2026Graph-structured data underpin a wide spectrum of modern applications. However, complex graph topologies and homophilic patterns can facilitate attribute inference attacks (AIAs) by enabling sensitive information leakage to propagate across local neighborhoods. Existing AIAs predominantly assume that adversaries can probe sensitive attributes through repeated model queries. Such assumptions are often impractical in real-world settings due to stringent data protection regulations, prohibitive query budgets, and heightened detection risks, especially when inferring multiple sensitive attributes. More critically, this model-centric perspective obscures a pervasive blind spot: \textbf{intrinsic multiple sensitive information leakage arising solely from publicly released graphs.} To exploit this unexplored vulnerability, we introduce a new attack paradigm and propose \textbf{Taipan, the first query-free transfer-based attack framework for multiple sensitive attribute inference attacks on graphs (G-MSAIAs).} Taipan integrates \emph{Hierarchical Attack Knowledge Routing} to capture intricate inter-attribute correlations, and \emph{Prompt-guided Attack Prototype Refinement} to mitigate negative transfer and performance degradation. We further present a systematic evaluation framework tailored to G-MSAIAs. Extensive experiments on diverse real-world graph datasets demonstrate that Taipan consistently achieves strong attack performance across same-distribution settings and heterogeneous similar- and out-of-distribution settings with mismatched feature dimensionalities, and remains effective even under rigorous differential privacy guarantees. Our findings underscore the urgent need for more robust multi-attribute privacy-preserving graph publishing methods and data-sharing practices.
GraphToxin: Reconstructing Full Unlearned Graphs from Graph Unlearning
Nov 14, 2025
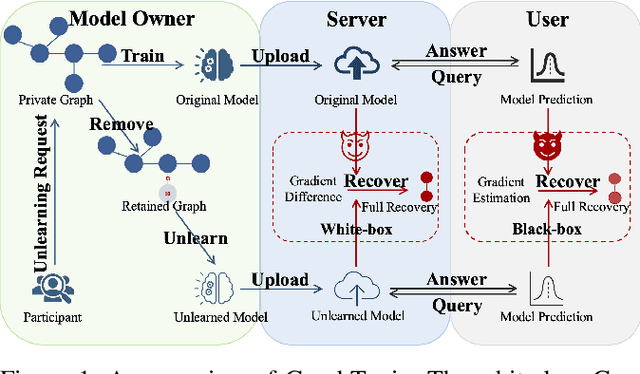


Graph unlearning has emerged as a promising solution for complying with "the right to be forgotten" regulations by enabling the removal of sensitive information upon request. However, this solution is not foolproof. The involvement of multiple parties creates new attack surfaces, and residual traces of deleted data can still remain in the unlearned graph neural networks. These vulnerabilities can be exploited by attackers to recover the supposedly erased samples, thereby undermining the inherent functionality of graph unlearning. In this work, we propose GraphToxin, the first graph reconstruction attack against graph unlearning. Specifically, we introduce a novel curvature matching module to provide a fine-grained guidance for full unlearned graph recovery. We demonstrate that GraphToxin can successfully subvert the regulatory guarantees expected from graph unlearning - it can recover not only a deleted individual's information and personal links but also sensitive content from their connections, thereby posing substantially more detrimental threats. Furthermore, we extend GraphToxin to multiple node removals under both white-box and black-box setting. We highlight the necessity of a worst-case analysis and propose a comprehensive evaluation framework to systematically assess the attack performance under both random and worst-case node removals. This provides a more robust and realistic measure of the vulnerability of graph unlearning methods to graph reconstruction attacks. Our extensive experiments demonstrate the effectiveness and flexibility of GraphToxin. Notably, we show that existing defense mechanisms are largely ineffective against this attack and, in some cases, can even amplify its performance. Given the severe privacy risks posed by GraphToxin, our work underscores the urgent need for the development of more effective and robust defense strategies against this attack.
SolRPDS: A Dataset for Analyzing Rug Pulls in Solana Decentralized Finance
Apr 06, 2025Rug pulls in Solana have caused significant damage to users interacting with Decentralized Finance (DeFi). A rug pull occurs when developers exploit users' trust and drain liquidity from token pools on Decentralized Exchanges (DEXs), leaving users with worthless tokens. Although rug pulls in Ethereum and Binance Smart Chain (BSC) have gained attention recently, analysis of rug pulls in Solana remains largely under-explored. In this paper, we introduce SolRPDS (Solana Rug Pull Dataset), the first public rug pull dataset derived from Solana's transactions. We examine approximately four years of DeFi data (2021-2024) that covers suspected and confirmed tokens exhibiting rug pull patterns. The dataset, derived from 3.69 billion transactions, consists of 62,895 suspicious liquidity pools. The data is annotated for inactivity states, which is a key indicator, and includes several detailed liquidity activities such as additions, removals, and last interaction as well as other attributes such as inactivity periods and withdrawn token amounts, to help identify suspicious behavior. Our preliminary analysis reveals clear distinctions between legitimate and fraudulent liquidity pools and we found that 22,195 tokens in the dataset exhibit rug pull patterns during the examined period. SolRPDS can support a wide range of future research on rug pulls including the development of data-driven and heuristic-based solutions for real-time rug pull detection and mitigation.
Krait: A Backdoor Attack Against Graph Prompt Tuning
Jul 18, 2024Graph prompt tuning has emerged as a promising paradigm to effectively transfer general graph knowledge from pre-trained models to various downstream tasks, particularly in few-shot contexts. However, its susceptibility to backdoor attacks, where adversaries insert triggers to manipulate outcomes, raises a critical concern. We conduct the first study to investigate such vulnerability, revealing that backdoors can disguise benign graph prompts, thus evading detection. We introduce Krait, a novel graph prompt backdoor. Specifically, we propose a simple yet effective model-agnostic metric called label non-uniformity homophily to select poisoned candidates, significantly reducing computational complexity. To accommodate diverse attack scenarios and advanced attack types, we design three customizable trigger generation methods to craft prompts as triggers. We propose a novel centroid similarity-based loss function to optimize prompt tuning for attack effectiveness and stealthiness. Experiments on four real-world graphs demonstrate that Krait can efficiently embed triggers to merely 0.15% to 2% of training nodes, achieving high attack success rates without sacrificing clean accuracy. Notably, in one-to-one and all-to-one attacks, Krait can achieve 100% attack success rates by poisoning as few as 2 and 22 nodes, respectively. Our experiments further show that Krait remains potent across different transfer cases, attack types, and graph neural network backbones. Additionally, Krait can be successfully extended to the black-box setting, posing more severe threats. Finally, we analyze why Krait can evade both classical and state-of-the-art defenses, and provide practical insights for detecting and mitigating this class of attacks.
MAPPING: Debiasing Graph Neural Networks for Fair Node Classification with Limited Sensitive Information Leakage
Jan 23, 2024Despite remarkable success in diverse web-based applications, Graph Neural Networks(GNNs) inherit and further exacerbate historical discrimination and social stereotypes, which critically hinder their deployments in high-stake domains such as online clinical diagnosis, financial crediting, etc. However, current fairness research that primarily craft on i.i.d data, cannot be trivially replicated to non-i.i.d. graph structures with topological dependence among samples. Existing fair graph learning typically favors pairwise constraints to achieve fairness but fails to cast off dimensional limitations and generalize them into multiple sensitive attributes; besides, most studies focus on in-processing techniques to enforce and calibrate fairness, constructing a model-agnostic debiasing GNN framework at the pre-processing stage to prevent downstream misuses and improve training reliability is still largely under-explored. Furthermore, previous work on GNNs tend to enhance either fairness or privacy individually but few probe into their interplays. In this paper, we propose a novel model-agnostic debiasing framework named MAPPING (\underline{M}asking \underline{A}nd \underline{P}runing and Message-\underline{P}assing train\underline{ING}) for fair node classification, in which we adopt the distance covariance($dCov$)-based fairness constraints to simultaneously reduce feature and topology biases in arbitrary dimensions, and combine them with adversarial debiasing to confine the risks of attribute inference attacks. Experiments on real-world datasets with different GNN variants demonstrate the effectiveness and flexibility of MAPPING. Our results show that MAPPING can achieve better trade-offs between utility and fairness, and mitigate privacy risks of sensitive information leakage.