 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsolidating and Developing Benchmarking Datasets for the Nepali Natural Language Understanding Tasks
Nov 28, 2024

The Nepali language has distinct linguistic features, especially its complex script (Devanagari script), morphology, and various dialects, which pose a unique challenge for natural language processing (NLP) evaluation. While the Nepali Language Understanding Evaluation (Nep-gLUE) benchmark provides a foundation for evaluating models, it remains limited in scope, covering four tasks. This restricts their utility for comprehensive assessments of NLP models. To address this limitation, we introduce eight new datasets, creating a new benchmark, the Nepali Language Understanding Evaluation (NLUE) benchmark, which covers a total of 12 tasks for evaluating the performance of models across a diverse set of Natural Language Understanding (NLU) tasks. The added tasks include single-sentence classification, similarity and paraphrase tasks, and Natural Language Inference (NLI) tasks. On evaluating the models using added tasks, we observe that the existing models fall short in handling complex NLU tasks effectively. This expanded benchmark sets a new standard for evaluating, comparing, and advancing models, contributing significantly to the broader goal of advancing NLP research for low-resource languages.
Development of Pre-Trained Transformer-based Models for the Nepali Language
Nov 24, 2024
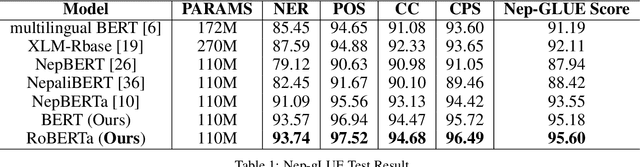
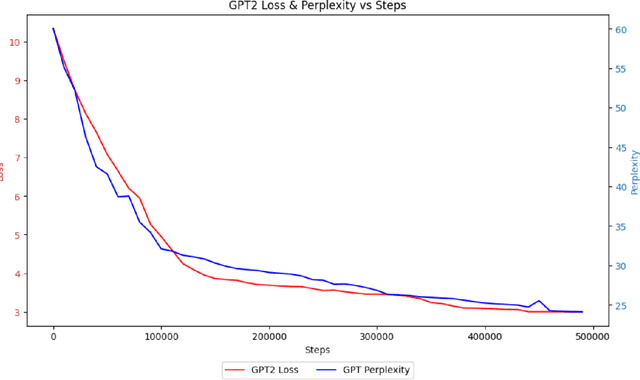

Transformer-based pre-trained language models have dominated the field of Natural Language Processing (NLP) for quite some time now. However, the Nepali language, spoken by approximately 32 million people worldwide, remains significantly underrepresented in this domain. This underrepresentation is primarily attributed to the scarcity of monolingual data corpora and limited available resources for the Nepali language. While existing efforts have predominantly concentrated on basic encoder-based models, there is a notable gap in the exploration of decoder-based architectures. To address this gap, we have collected 27.5 GB of Nepali text data, approximately 2.4x larger than any previously available Nepali language corpus. Leveraging this data, we pre-trained three different models i.e., BERT, RoBERTa, and GPT-2, exclusively for the Nepali Language. Furthermore, we performed instruction tuning and explored its potential for monolingual Nepali data, providing a foundation for future research. Our models outperformed the existing best model by 2 points on Nep-gLUE benchmark, scoring 95.60 and also outperformed existing models on text generation tasks, demonstrating improvements in both understanding and generating Nepali text.
A Comprehensive Study of the Current State-of-the-Art in Nepali Automatic Speech Recognition Systems
Feb 05, 2024In this paper, we examine the research conducted in the field of Nepali Automatic Speech Recognition (ASR). The primary objective of this survey is to conduct a comprehensive review of the works on Nepali Automatic Speech Recognition Systems completed to date, explore the different datasets used, examine the technology utilized, and take account of the obstacles encountered in implementing the Nepali ASR system. In tandem with the global trends of ever-increasing research on speech recognition based research, the number of Nepalese ASR-related projects are also growing. Nevertheless, the investigation of language and acoustic models of the Nepali language has not received adequate attention compared to languages that possess ample resources. In this context, we provide a framework as well as directions for future investigations.
Nepali Video Captioning using CNN-RNN Architecture
Nov 05, 2023



This article presents a study on Nepali video captioning using deep neural networks. Through the integration of pre-trained CNNs and RNNs, the research focuses on generating precise and contextually relevant captions for Nepali videos. The approach involves dataset collection, data preprocessing, model implementation, and evaluation. By enriching the MSVD dataset with Nepali captions via Google Translate, the study trains various CNN-RNN architectures. The research explores the effectiveness of CNNs (e.g., EfficientNetB0, ResNet101, VGG16) paired with different RNN decoders like LSTM, GRU, and BiLSTM. Evaluation involves BLEU and METEOR metrics, with the best model being EfficientNetB0 + BiLSTM with 1024 hidden dimensions, achieving a BLEU-4 score of 17 and METEOR score of 46. The article also outlines challenges and future directions for advancing Nepali video captioning, offering a crucial resource for further research in this area.
* 6 pages, 5 figures, 3 tables. Presented in the International Conference on Technologies for Computer, Electrical, Electronics & Communication (ICT-CEEL 2023), Bhaktapur, Nepal