 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Herb Identification Using Transfer Learning: A CNN-Powered Mobile Application for Nepalese Flora
May 04, 2025Herb classification presents a critical challenge in botanical research, particularly in regions with rich biodiversity such as Nepal. This study introduces a novel deep learning approach for classifying 60 different herb species using Convolutional Neural Networks (CNNs) and transfer learning techniques. Using a manually curated dataset of 12,000 herb images, we developed a robust machine learning model that addresses existing limitations in herb recognition methodologies. Our research employed multiple model architectures, including DenseNet121, 50-layer Residual Network (ResNet50), 16-layer Visual Geometry Group Network (VGG16), InceptionV3, EfficientNetV2, and Vision Transformer (VIT), with DenseNet121 ultimately demonstrating superior performance. Data augmentation and regularization techniques were applied to mitigate overfitting and enhance the generalizability of the model. This work advances herb classification techniques, preserving traditional botanical knowledge and promoting sustainable herb utilization.
Consolidating and Developing Benchmarking Datasets for the Nepali Natural Language Understanding Tasks
Nov 28, 2024

The Nepali language has distinct linguistic features, especially its complex script (Devanagari script), morphology, and various dialects, which pose a unique challenge for natural language processing (NLP) evaluation. While the Nepali Language Understanding Evaluation (Nep-gLUE) benchmark provides a foundation for evaluating models, it remains limited in scope, covering four tasks. This restricts their utility for comprehensive assessments of NLP models. To address this limitation, we introduce eight new datasets, creating a new benchmark, the Nepali Language Understanding Evaluation (NLUE) benchmark, which covers a total of 12 tasks for evaluating the performance of models across a diverse set of Natural Language Understanding (NLU) tasks. The added tasks include single-sentence classification, similarity and paraphrase tasks, and Natural Language Inference (NLI) tasks. On evaluating the models using added tasks, we observe that the existing models fall short in handling complex NLU tasks effectively. This expanded benchmark sets a new standard for evaluating, comparing, and advancing models, contributing significantly to the broader goal of advancing NLP research for low-resource languages.
Development of Pre-Trained Transformer-based Models for the Nepali Language
Nov 24, 2024
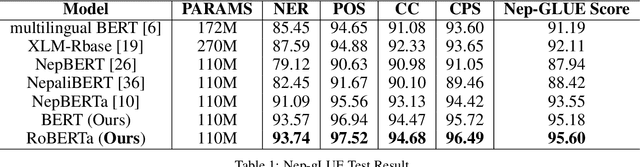
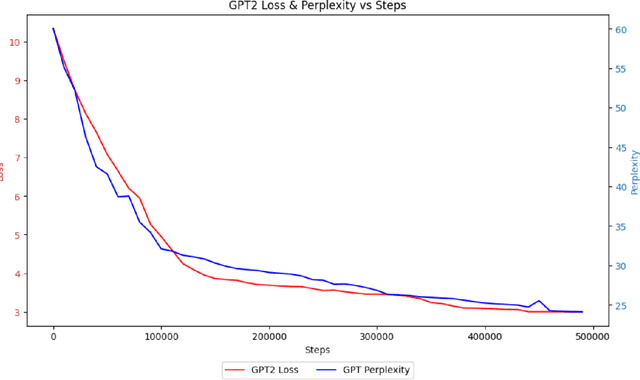

Transformer-based pre-trained language models have dominated the field of Natural Language Processing (NLP) for quite some time now. However, the Nepali language, spoken by approximately 32 million people worldwide, remains significantly underrepresented in this domain. This underrepresentation is primarily attributed to the scarcity of monolingual data corpora and limited available resources for the Nepali language. While existing efforts have predominantly concentrated on basic encoder-based models, there is a notable gap in the exploration of decoder-based architectures. To address this gap, we have collected 27.5 GB of Nepali text data, approximately 2.4x larger than any previously available Nepali language corpus. Leveraging this data, we pre-trained three different models i.e., BERT, RoBERTa, and GPT-2, exclusively for the Nepali Language. Furthermore, we performed instruction tuning and explored its potential for monolingual Nepali data, providing a foundation for future research. Our models outperformed the existing best model by 2 points on Nep-gLUE benchmark, scoring 95.60 and also outperformed existing models on text generation tasks, demonstrating improvements in both understanding and generating Nepali text.