 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALERT: Adapting Language Models to Reasoning Tasks
Dec 16, 2022


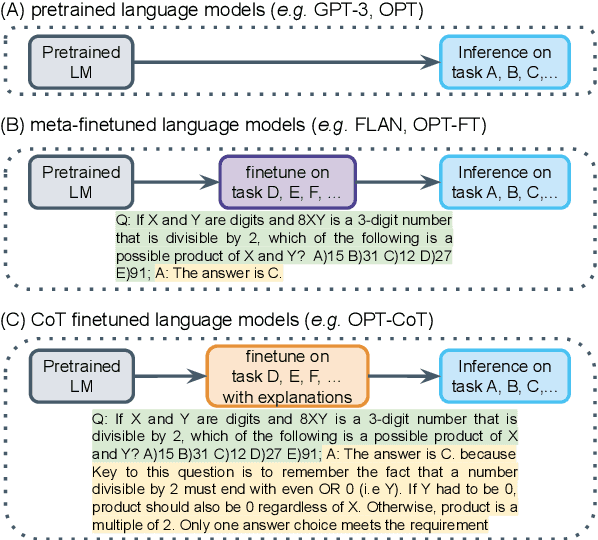
Current large language models can perform reasonably well on complex tasks that require step-by-step reasoning with few-shot learning. Are these models applying reasoning skills they have learnt during pre-training and reason outside of their training context, or are they simply memorizing their training corpus at finer granularity and have learnt to better understand their context? To tease apart these possibilities, we introduce ALERT, a benchmark and suite of analyses for assessing language models' reasoning ability comparing pre-trained and finetuned models on complex tasks that require reasoning skills to solve. ALERT provides a test bed to asses any language model on fine-grained reasoning skills, which spans over 20 datasets and covers 10 different reasoning skills. We leverage ALERT to further investigate the role of finetuning. With extensive empirical analysis we find that language models learn more reasoning skills such as textual entailment, abductive reasoning, and analogical reasoning during finetuning stage compared to pretraining state. We also find that when language models are finetuned they tend to overfit to the prompt template, which hurts the robustness of models causing generalization problems.