 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetRoBERTa: Leveraging Traditional Customer Relationship Management Data to Develop a Transit-Topic-Aware Language Model
Aug 09, 2023Transit riders' feedback provided in ridership surveys, customer relationship management (CRM) channels, and in more recent times, through social media is key for transit agencies to better gauge the efficacy of their services and initiatives. Getting a holistic understanding of riders' experience through the feedback shared in those instruments is often challenging, mostly due to the open-ended, unstructured nature of text feedback. In this paper, we propose leveraging traditional transit CRM feedback to develop and deploy a transit-topic-aware large language model (LLM) capable of classifying open-ended text feedback to relevant transit-specific topics. First, we utilize semi-supervised learning to engineer a training dataset of 11 broad transit topics detected in a corpus of 6 years of customer feedback provided to the Washington Metropolitan Area Transit Authority (WMATA). We then use this dataset to train and thoroughly evaluate a language model based on the RoBERTa architecture. We compare our LLM, MetRoBERTa, to classical machine learning approaches utilizing keyword-based and lexicon representations. Our model outperforms those methods across all evaluation metrics, providing an average topic classification accuracy of 90%. Finally, we provide a value proposition of this work demonstrating how the language model, alongside additional text processing tools, can be applied to add structure to open-ended text sources of feedback like Twitter. The framework and results we present provide a pathway for an automated, generalizable approach for ingesting, visualizing, and reporting transit riders' feedback at scale, enabling agencies to better understand and improve customer experience.
Computer Vision for Transit Travel Time Prediction: An End-to-End Framework Using Roadside Urban Imagery
Dec 13, 2022Accurate travel time estimation is paramount for providing transit users with reliable schedules and dependable real-time information. This paper is the first to utilize roadside urban imagery for direct transit travel time prediction. We propose and evaluate an end-to-end framework integrating traditional transit data sources with a roadside camera for automated roadside image data acquisition, labeling, and model training to predict transit travel times across a segment of interest. First, we show how the GTFS real-time data can be utilized as an efficient activation mechanism for a roadside camera unit monitoring a segment of interest. Second, AVL data is utilized to generate ground truth labels for the acquired images based on the observed transit travel time percentiles across the camera-monitored segment during the time of image acquisition. Finally, the generated labeled image dataset is used to train and thoroughly evaluate a Vision Transformer (ViT) model to predict a discrete transit travel time range (band). The results illustrate that the ViT model is able to learn image features and contents that best help it deduce the expected travel time range with an average validation accuracy ranging between 80%-85%. We assess the interpretability of the ViT model's predictions and showcase how this discrete travel time band prediction can subsequently improve continuous transit travel time estimation. The workflow and results presented in this study provide an end-to-end, scalable, automated, and highly efficient approach for integrating traditional transit data sources and roadside imagery to improve the estimation of transit travel duration. This work also demonstrates the value of incorporating real-time information from computer-vision sources, which are becoming increasingly accessible and can have major implications for improving operations and passenger real-time information.
An Assessment of Safety-Based Driver Behavior Modeling in Microscopic Simulation Utilizing Real-Time Vehicle Trajectories
Oct 17, 2022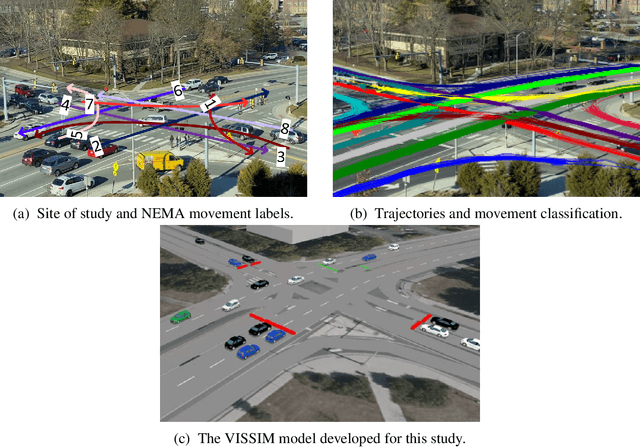
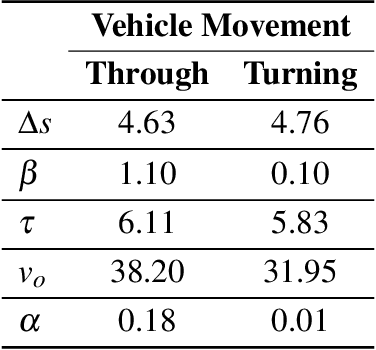

Accurate representation of observed driving behavior is critical for effectively evaluating safety and performance interventions in simulation modeling. In this study, we implement and evaluate a safety-based Optimal Velocity Model (OVM) to provide a high-fidelity replication of safety-critical behavior in microscopic simulation and showcase its implications for safety-focused assessments of traffic control strategies. A comprehensive simulation model is created for the site of study in PTV VISSIM utilizing detailed vehicle trajectory information extracted from real-time video inference, which are also used to calibrate the parameters of the safety-based OVM to replicate the observed driving behavior in the site of study. The calibrated model is then incorporated as an external driver model that overtakes VISSIM's default Wiedemann 74 model during simulated car-following episodes. The results of the preliminary analysis show the significant improvements achieved by using our model in replicating the existing safety conflicts observed at the site of the study. We then utilize this improved representation of the status quo to assess the potential impact of different scenarios of signal control and speed limit enforcement in reducing those existing conflicts by up to 23%. The results of this study showcase the considerable improvements that can be achieved by utilizing data-driven car-following behavior modeling, and the workflow presented provides an end-to-end, scalable, automated, and generalizable approach for replicating the existing driving behavior observed at a site of interest in microscopic simulation by utilizing vehicle trajectories efficiently extracted via roadside video inference.
A Framework for Real-time Traffic Trajectory Tracking, Speed Estimation, and Driver Behavior Calibration at Urban Intersections Using Virtual Traffic Lanes
Jun 18, 2021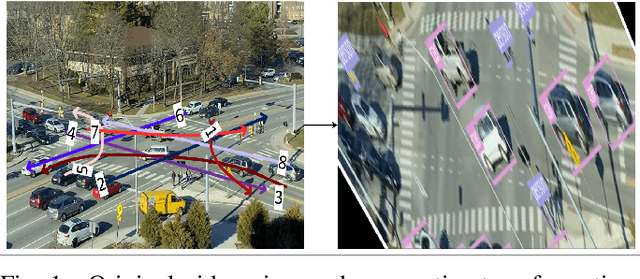
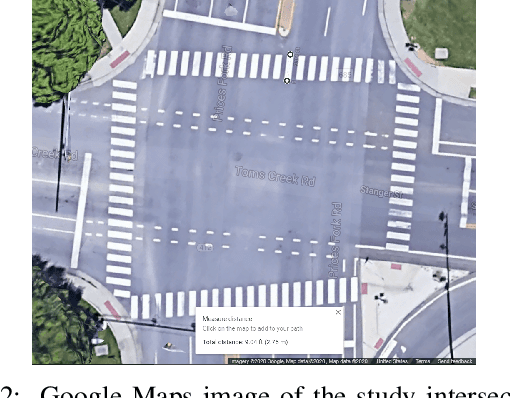


In a previous study, we presented VT-Lane, a three-step framework for real-time vehicle detection, tracking, and turn movement classification at urban intersections. In this study, we present a case study incorporating the highly accurate trajectories and movement classification obtained via VT-Lane for the purpose of speed estimation and driver behavior calibration for traffic at urban intersections. First, we use a highly instrumented vehicle to verify the estimated speeds obtained from video inference. The results of the speed validation show that our method can estimate the average travel speed of detected vehicles in real-time with an error of 0.19 m/sec, which is equivalent to 2% of the average observed travel speeds in the intersection of the study. Instantaneous speeds (at the resolution of 30 Hz) were found to be estimated with an average error of 0.21 m/sec and 0.86 m/sec respectively for free-flowing and congested traffic conditions. We then use the estimated speeds to calibrate the parameters of a driver behavior model for the vehicles in the area of study. The results show that the calibrated model replicates the driving behavior with an average error of 0.45 m/sec, indicating the high potential for using this framework for automated, large-scale calibration of car-following models from roadside traffic video data, which can lead to substantial improvements in traffic modeling via microscopic simulation.
Privacy Concerns Regarding Occupant Tracking in Smart Buildings
Sep 30, 2020
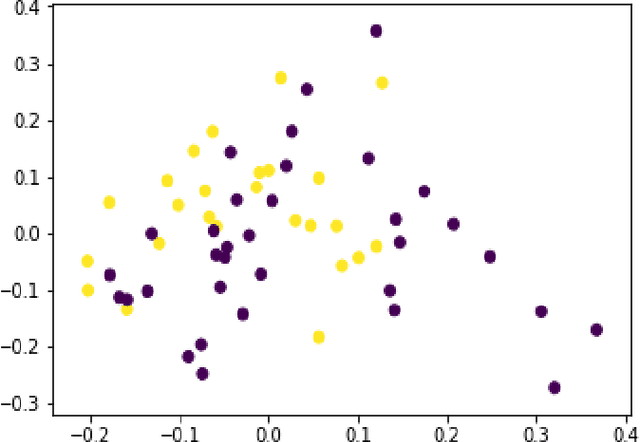
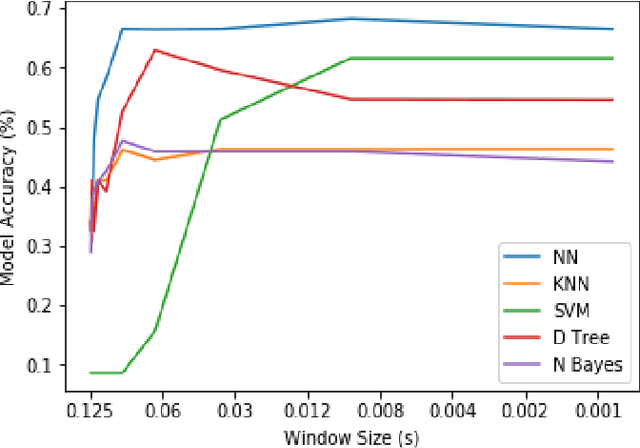
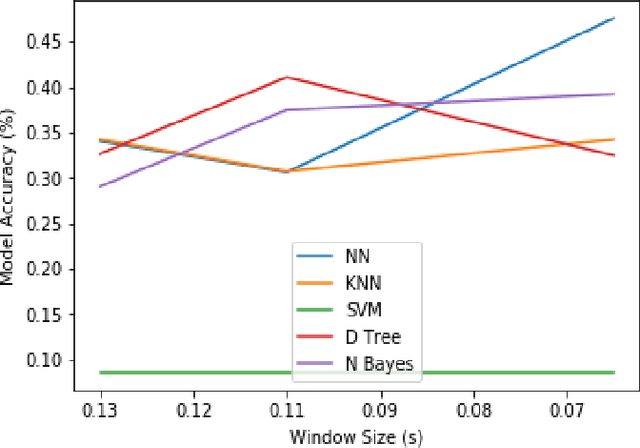
Tracking of occupants within buildings has become a topic of interest in the past decade. Occupant tracking has been used in the public safety, energy conservation, and marketing fields. Various methods have been demonstrated which can track people outside of and inside buildings; including GPS, visual-based tracking using surveillance cameras, and vibration-based tracking using sensors such as accelerometers. In this work, those main systems for tracking occupants are compared and contrasted for the levels of detail they give about where occupants are, as well as their respective privacy concerns and how identifiable the tracking information collected is to a specific person. We discuss a case study using vibrations sensors mounted in Virginia Tech's Goodwin Hall that was recently conducted, demonstrating that similar levels of accuracy in occupant localization can be achieved to current methods, and highlighting the amount of identifying information in the vibration signals dataset. Finally, a method of transforming the vibration data to preserve occupant privacy was proposed and tested on the dataset. The results indicate that our proposed method has successfully resulted in anonymizing the occupant's gender information which was previously identifiable from the vibration data, while minimally impacting the localization accuracy achieved without anonymization.