 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering Product-Questions by Utilizing Questions from Other Contextually Similar Products
May 19, 2021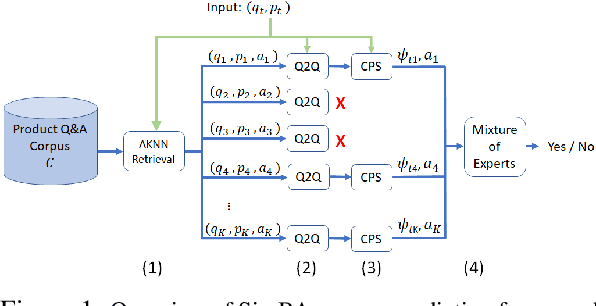



Predicting the answer to a product-related question is an emerging field of research that recently attracted a lot of attention. Answering subjective and opinion-based questions is most challenging due to the dependency on customer-generated content. Previous works mostly focused on review-aware answer prediction; however, these approaches fail for new or unpopular products, having no (or only a few) reviews at hand. In this work, we propose a novel and complementary approach for predicting the answer for such questions, based on the answers for similar questions asked on similar products. We measure the contextual similarity between products based on the answers they provide for the same question. A mixture-of-expert framework is used to predict the answer by aggregating the answers from contextually similar products. Empirical results demonstrate that our model outperforms strong baselines on some segments of questions, namely those that have roughly ten or more similar resolved questions in the corpus. We additionally publish two large-scale datasets used in this work, one is of similar product question pairs, and the second is of product question-answer pairs.
Confidence Estimation in Structured Prediction
Nov 06, 2011

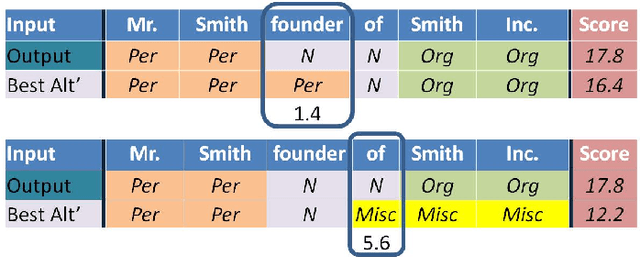

Structured classification tasks such as sequence labeling and dependency parsing have seen much interest by the Natural Language Processing and the machine learning communities. Several online learning algorithms were adapted for structured tasks such as Perceptron, Passive- Aggressive and the recently introduced Confidence-Weighted learning . These online algorithms are easy to implement, fast to train and yield state-of-the-art performance. However, unlike probabilistic models like Hidden Markov Model and Conditional random fields, these methods generate models that output merely a prediction with no additional information regarding confidence in the correctness of the output. In this work we fill the gap proposing few alternatives to compute the confidence in the output of non-probabilistic algorithms.We show how to compute confidence estimates in the prediction such that the confidence reflects the probability that the word is labeled correctly. We then show how to use our methods to detect mislabeled words, trade recall for precision and active learning. We evaluate our methods on four noun-phrase chunking and named entity recognition sequence labeling tasks, and on dependency parsing for 14 languages.