 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA semi-supervised sparse K-Means algorithm
Mar 20, 2020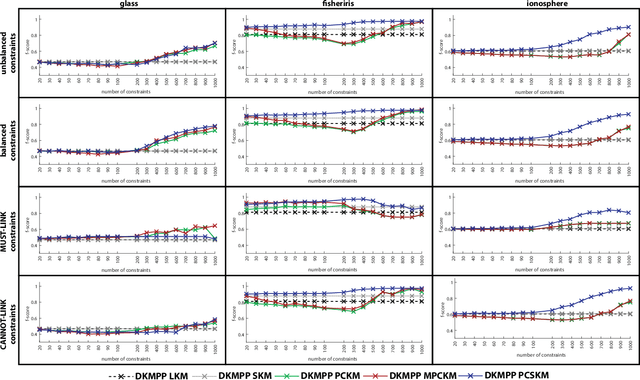

We consider the problem of data clustering with unidentified feature quality but the existence of small amount of label data. In the first case a sparse clustering method can be employed in order to detect the subgroup of features necessary for clustering and in the second case a semi-supervised method can use the labelled data to create constraints and enhance the clustering solution. In this paper we propose a K-Means inspired algorithm that employs these techniques. We show that the algorithm maintains the high performance of other similar semi-supervised algorthms as well as keeping the ability to identify informative from uninformative features. We examine the performance of the algorithm on real world data sets with unknown features quality as well as a real world data set with a known uninformative feature. We use a series of scenarios with different number and types of constraints.
An empirical comparison between stochastic and deterministic centroid initialisation for K-Means variations
Oct 09, 2019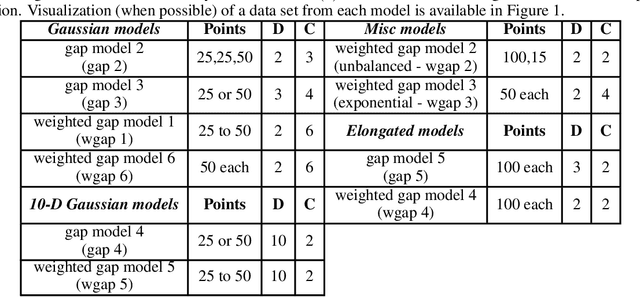
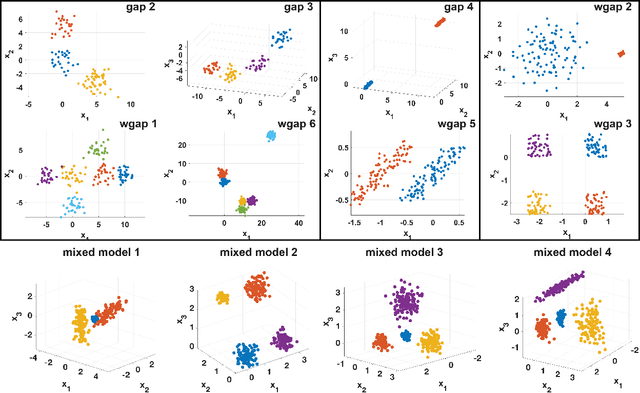
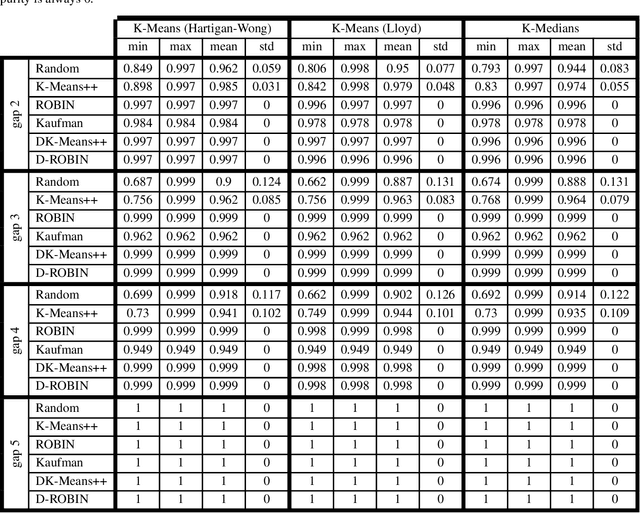
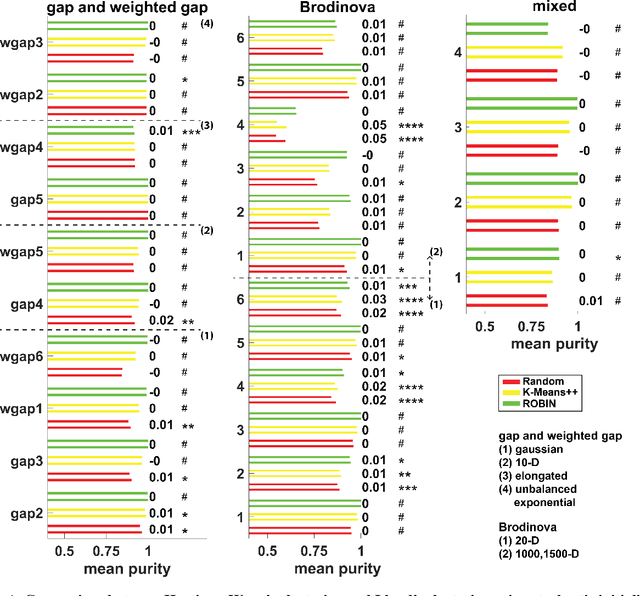
K-Means is one of the most used algorithms for data clustering and the usual clustering method for benchmarking. Despite its wide application it is well-known that it suffers from a series of disadvantages, such as the positions of the initial clustering centres (centroids), which can greatly affect the clustering solution. Over the years many K-Means variations and initialisations techniques have been proposed with different degrees of complexity. In this study we focus on common K-Means variations and deterministic initialisation techniques and we first show that more sophisticated initialisation methods reduce or alleviates the need of complex K-Means clustering, and secondly, that deterministic methods can achieve equivalent or better performance than stochastic methods. These conclusions are obtained through extensive benchmarking using different model data sets from various studies as well as clustering data sets.
A generalised framework for detailed classification of swimming paths inside the Morris Water Maze
Dec 18, 2017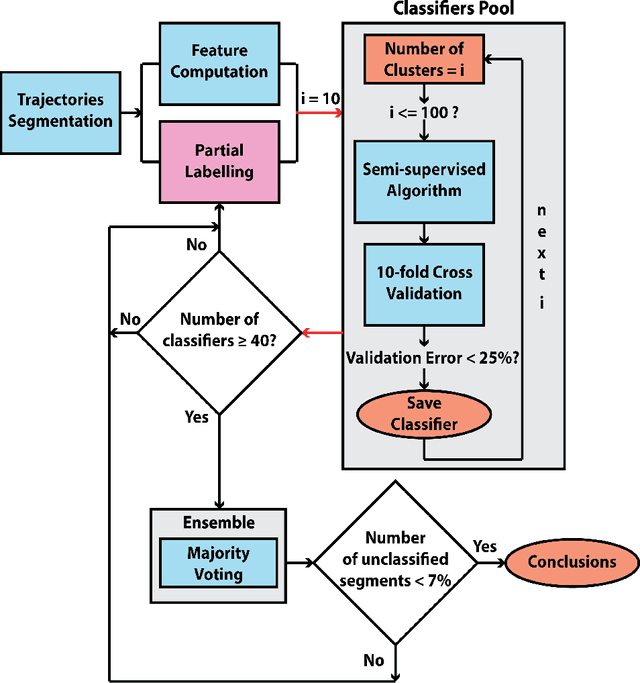
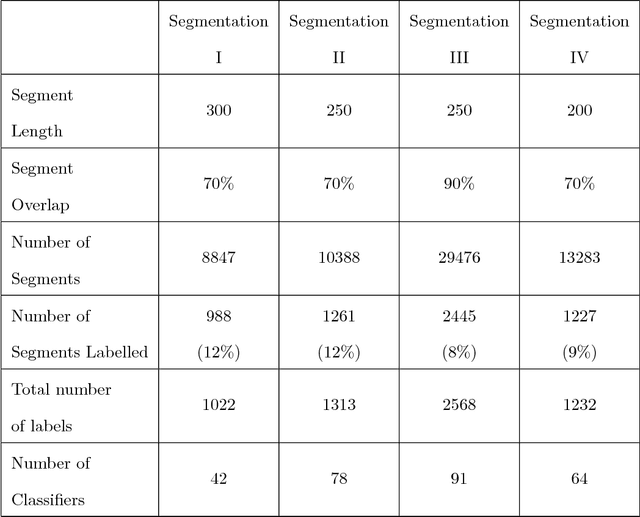
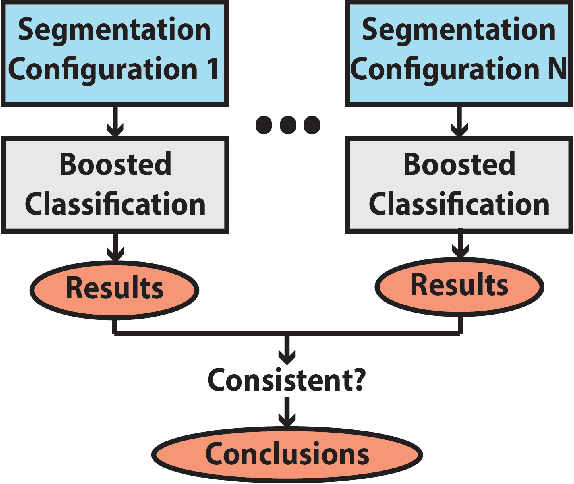
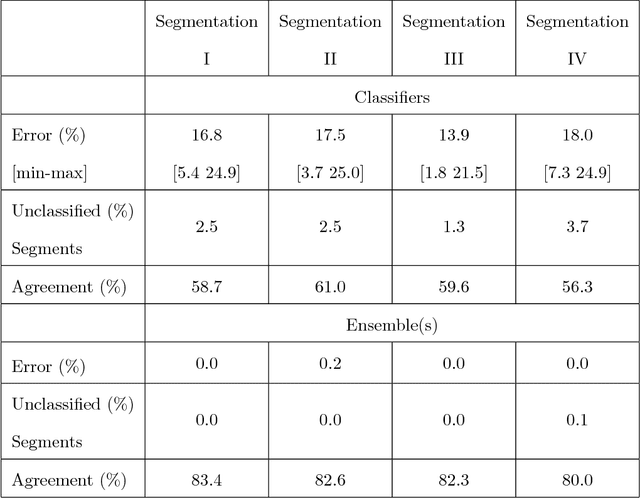
The Morris Water Maze is commonly used in behavioural neuroscience for the study of spatial learning with rodents. Over the years, various methods of analysing rodent data collected in this task have been proposed. These methods span from classical performance measurements (e.g. escape latency, rodent speed, quadrant preference) to more sophisticated methods of categorisation which classify the animal swimming path into behavioural classes known as strategies. Classification techniques provide additional insight in relation to the actual animal behaviours but still only a limited amount of studies utilise them mainly because they highly depend on machine learning knowledge. We have previously demonstrated that the animals implement various strategies and by classifying whole trajectories can lead to the loss of important information. In this work, we developed a generalised and robust classification methodology which implements majority voting to boost the classification performance and successfully nullify the need of manual tuning. Based on this framework, we built a complete software, capable of performing the full analysis described in this paper. The software provides an easy to use graphical user interface (GUI) through which users can enter their trajectory data, segment and label them and finally generate reports and figures of the results.