 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Multi-Fidelity Bayesian Optimization in Chemistry: Open Challenges and Major Considerations
Sep 11, 2024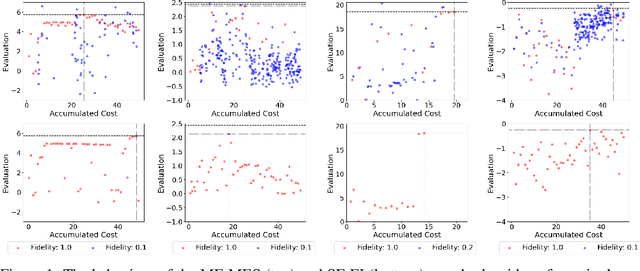

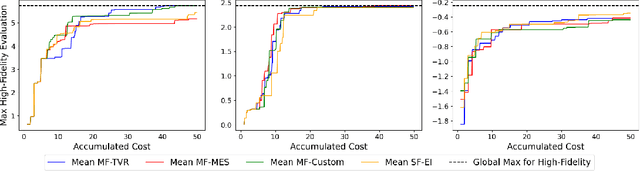
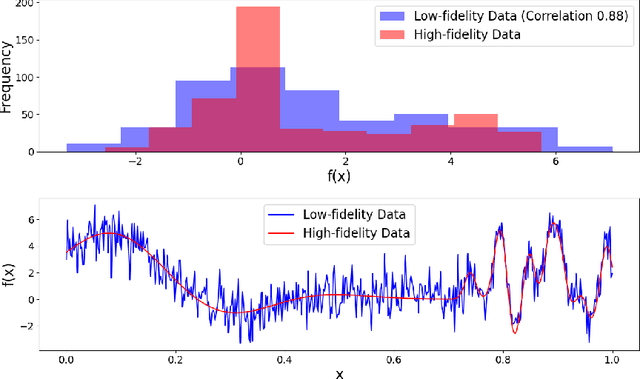
Multi fidelity Bayesian optimization (MFBO) leverages experimental and or computational data of varying quality and resource cost to optimize towards desired maxima cost effectively. This approach is particularly attractive for chemical discovery due to MFBO's ability to integrate diverse data sources. Here, we investigate the application of MFBO to accelerate the identification of promising molecules or materials. We specifically analyze the conditions under which lower fidelity data can enhance performance compared to single-fidelity problem formulations. We address two key challenges, selecting the optimal acquisition function, understanding the impact of cost, and data fidelity correlation. We then discuss how to assess the effectiveness of MFBO for chemical discovery.
PolyCL: Contrastive Learning for Polymer Representation Learning via Explicit and Implicit Augmentations
Aug 14, 2024



Polymers play a crucial role in a wide array of applications due to their diverse and tunable properties. Establishing the relationship between polymer representations and their properties is crucial to the computational design and screening of potential polymers via machine learning. The quality of the representation significantly influences the effectiveness of these computational methods. Here, we present a self-supervised contrastive learning paradigm, PolyCL, for learning high-quality polymer representation without the need for labels. Our model combines explicit and implicit augmentation strategies for improved learning performance. The results demonstrate that our model achieves either better, or highly competitive, performances on transfer learning tasks as a feature extractor without an overcomplicated training strategy or hyperparameter optimisation. Further enhancing the efficacy of our model, we conducted extensive analyses on various augmentation combinations used in contrastive learning. This led to identifying the most effective combination to maximise PolyCL's performance.