 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMART: A Flexible Approach to Regression using Spline-Based Multivariate Adaptive Regression Trees
Oct 08, 2024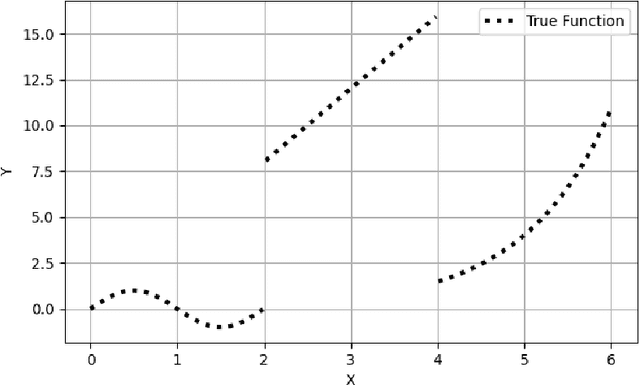

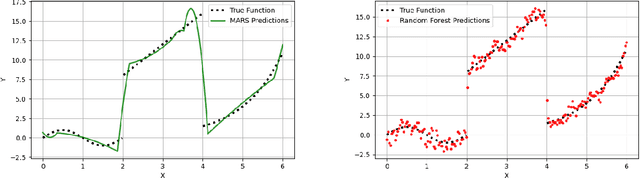
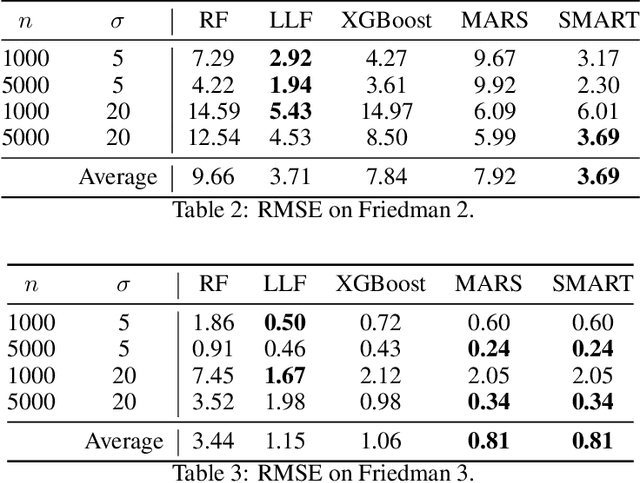
Decision trees are powerful for predictive modeling but often suffer from high variance when modeling continuous relationships. While algorithms like Multivariate Adaptive Regression Splines (MARS) excel at capturing such continuous relationships, they perform poorly when modeling discontinuities. To address the limitations of both approaches, we introduce Spline-based Multivariate Adaptive Regression Trees (SMART), which uses a decision tree to identify subsets of data with distinct continuous relationships and then leverages MARS to fit these relationships independently. Unlike other methods that rely on the tree structure to model interaction and higher-order terms, SMART leverages MARS's native ability to handle these terms, allowing the tree to focus solely on identifying discontinuities in the relationship. We test SMART on various datasets, demonstrating its improvement over state-of-the-art methods in such cases. Additionally, we provide an open-source implementation of our method to be used by practitioners.
Distributional Clustering: A distribution-preserving clustering method
Nov 14, 2019



One key use of k-means clustering is to identify cluster prototypes which can serve as representative points for a dataset. However, a drawback of using k-means cluster centers as representative points is that such points distort the distribution of the underlying data. This can be highly disadvantageous in problems where the representative points are subsequently used to gain insights on the data distribution, as these points do not mimic the distribution of the data. To this end, we propose a new clustering method called "distributional clustering", which ensures cluster centers capture the distribution of the underlying data. We first prove the asymptotic convergence of the proposed cluster centers to the data generating distribution, then present an efficient algorithm for computing these cluster centers in practice. Finally, we demonstrate the effectiveness of distributional clustering on synthetic and real datasets.