 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnPrem.LLM: A Privacy-Conscious Document Intelligence Toolkit
May 13, 2025We present OnPrem$.$LLM, a Python-based toolkit for applying large language models (LLMs) to sensitive, non-public data in offline or restricted environments. The system is designed for privacy-preserving use cases and provides prebuilt pipelines for document processing and storage, retrieval-augmented generation (RAG), information extraction, summarization, classification, and prompt/output processing with minimal configuration. OnPrem$.$LLM supports multiple LLM backends -- including llama$.$cpp, Ollama, vLLM, and Hugging Face Transformers -- with quantized model support, GPU acceleration, and seamless backend switching. Although designed for fully local execution, OnPrem$.$LLM also supports integration with a wide range of cloud LLM providers when permitted, enabling hybrid deployments that balance performance with data control. A no-code web interface extends accessibility to non-technical users.
CausalNLP: A Practical Toolkit for Causal Inference with Text
Jun 21, 2021
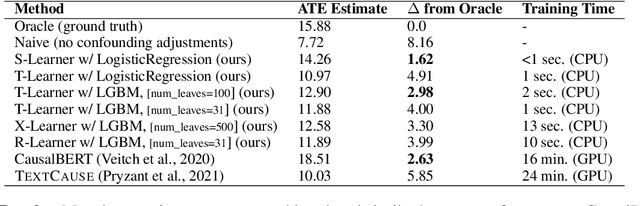
The vast majority of existing methods and systems for causal inference assume that all variables under consideration are categorical or numerical (e.g., gender, price, blood pressure, enrollment). In this paper, we present CausalNLP, a toolkit for inferring causality from observational data that includes text in addition to traditional numerical and categorical variables. CausalNLP employs the use of meta-learners for treatment effect estimation and supports using raw text and its linguistic properties as both a treatment and a "controlled-for" variable (e.g., confounder). The library is open-source and available at: https://github.com/amaiya/causalnlp.
ktrain: A Low-Code Library for Augmented Machine Learning
Apr 30, 2020We present ktrain, a low-code Python library that makes machine learning more accessible and easier to apply. As a wrapper to TensorFlow and many other libraries (e.g., transformers, scikit-learn, stellargraph), it is designed to make sophisticated, state-of-the-art machine learning models simple to build, train, inspect, and deploy by both beginners and experienced practitioners. Featuring modules that support text data (e.g., text classification, sequence tagging, open-domain question-answering), vision data (e.g., image classification), and graph data (e.g., node classification, link prediction), ktrain presents a simple unified interface enabling one to quickly solve a wide range of tasks in as little as three or four "commands" or lines of code.
A Framework for Comparing Groups of Documents
Aug 24, 2015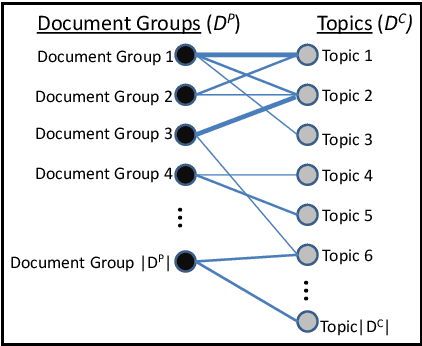



We present a general framework for comparing multiple groups of documents. A bipartite graph model is proposed where document groups are represented as one node set and the comparison criteria are represented as the other node set. Using this model, we present basic algorithms to extract insights into similarities and differences among the document groups. Finally, we demonstrate the versatility of our framework through an analysis of NSF funding programs for basic research.
Mining Measured Information from Text
May 05, 2015
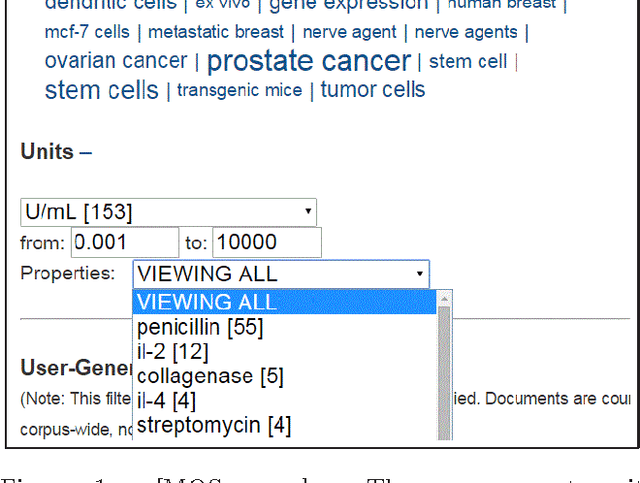


We present an approach to extract measured information from text (e.g., a 1370 degrees C melting point, a BMI greater than 29.9 kg/m^2 ). Such extractions are critically important across a wide range of domains - especially those involving search and exploration of scientific and technical documents. We first propose a rule-based entity extractor to mine measured quantities (i.e., a numeric value paired with a measurement unit), which supports a vast and comprehensive set of both common and obscure measurement units. Our method is highly robust and can correctly recover valid measured quantities even when significant errors are introduced through the process of converting document formats like PDF to plain text. Next, we describe an approach to extracting the properties being measured (e.g., the property "pixel pitch" in the phrase "a pixel pitch as high as 352 {\mu}m"). Finally, we present MQSearch: the realization of a search engine with full support for measured information.
Topic Similarity Networks: Visual Analytics for Large Document Sets
Sep 26, 2014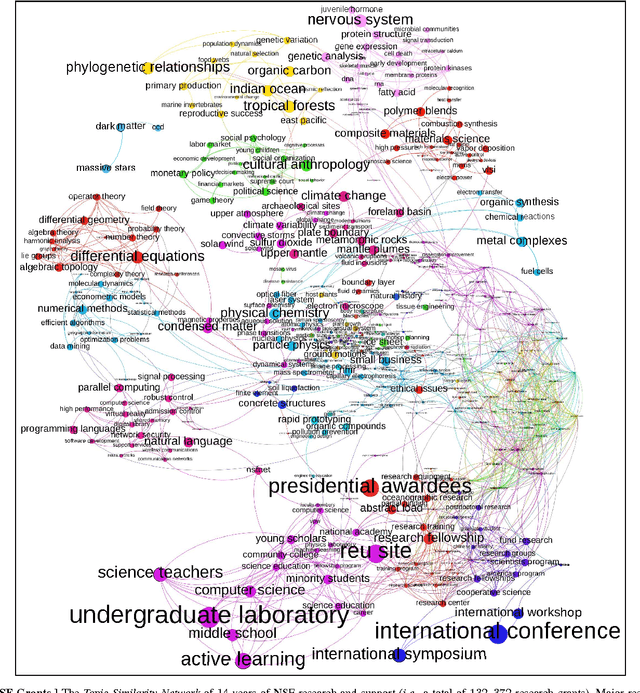



We investigate ways in which to improve the interpretability of LDA topic models by better analyzing and visualizing their outputs. We focus on examining what we refer to as topic similarity networks: graphs in which nodes represent latent topics in text collections and links represent similarity among topics. We describe efficient and effective approaches to both building and labeling such networks. Visualizations of topic models based on these networks are shown to be a powerful means of exploring, characterizing, and summarizing large collections of unstructured text documents. They help to "tease out" non-obvious connections among different sets of documents and provide insights into how topics form larger themes. We demonstrate the efficacy and practicality of these approaches through two case studies: 1) NSF grants for basic research spanning a 14 year period and 2) the entire English portion of Wikipedia.
Exploratory Analysis of Highly Heterogeneous Document Collections
Aug 11, 2013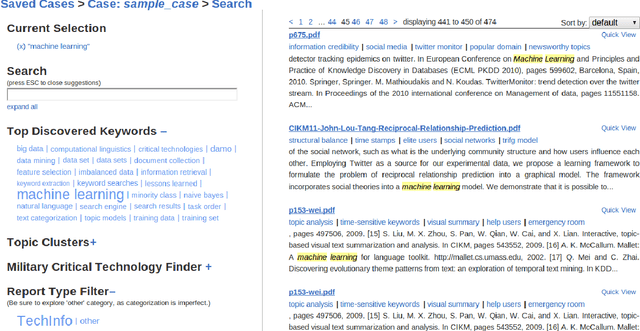



We present an effective multifaceted system for exploratory analysis of highly heterogeneous document collections. Our system is based on intelligently tagging individual documents in a purely automated fashion and exploiting these tags in a powerful faceted browsing framework. Tagging strategies employed include both unsupervised and supervised approaches based on machine learning and natural language processing. As one of our key tagging strategies, we introduce the KERA algorithm (Keyword Extraction for Reports and Articles). KERA extracts topic-representative terms from individual documents in a purely unsupervised fashion and is revealed to be significantly more effective than state-of-the-art methods. Finally, we evaluate our system in its ability to help users locate documents pertaining to military critical technologies buried deep in a large heterogeneous sea of information.