 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Similarity Networks: Visual Analytics for Large Document Sets
Paper and Code
Sep 26, 2014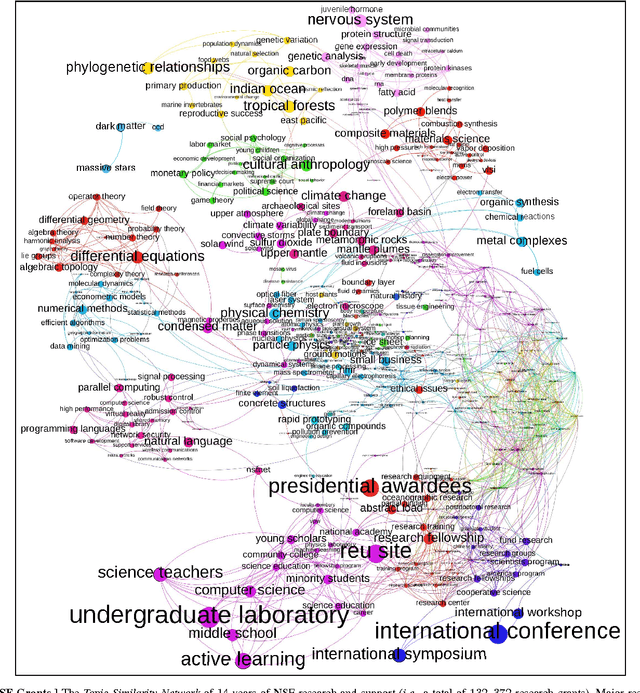



We investigate ways in which to improve the interpretability of LDA topic models by better analyzing and visualizing their outputs. We focus on examining what we refer to as topic similarity networks: graphs in which nodes represent latent topics in text collections and links represent similarity among topics. We describe efficient and effective approaches to both building and labeling such networks. Visualizations of topic models based on these networks are shown to be a powerful means of exploring, characterizing, and summarizing large collections of unstructured text documents. They help to "tease out" non-obvious connections among different sets of documents and provide insights into how topics form larger themes. We demonstrate the efficacy and practicality of these approaches through two case studies: 1) NSF grants for basic research spanning a 14 year period and 2) the entire English portion of Wikipedia.