 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Temporal Reasoning for Temporal Information Extraction from Text
May 15, 2020


Time is deeply woven into how people perceive, and communicate about the world. Almost unconsciously, we provide our language utterances with temporal cues, like verb tenses, and we can hardly produce sentences without such cues. Extracting temporal cues from text, and constructing a global temporal view about the order of described events is a major challenge of automatic natural language understanding. Temporal reasoning, the process of combining different temporal cues into a coherent temporal view, plays a central role in temporal information extraction. This article presents a comprehensive survey of the research from the past decades on temporal reasoning for automatic temporal information extraction from text, providing a case study on the integration of symbolic reasoning with machine learning-based information extraction systems.
Binary and Multitask Classification Model for Dutch Anaphora Resolution: Die/Dat Prediction
Jan 09, 2020
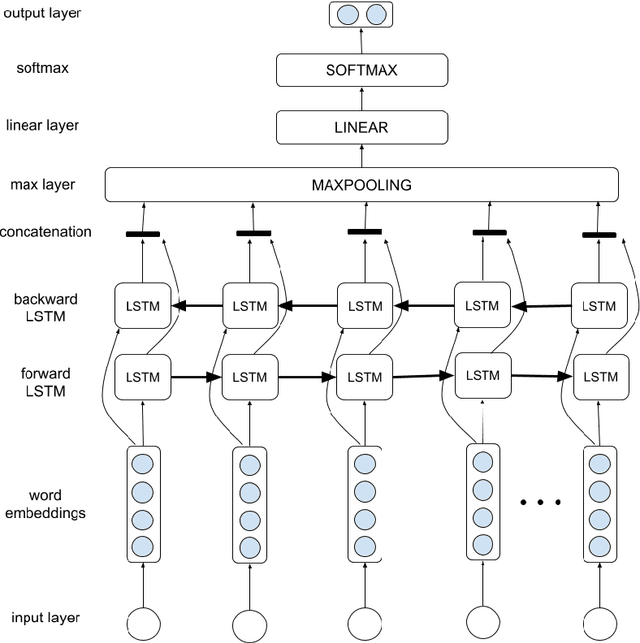
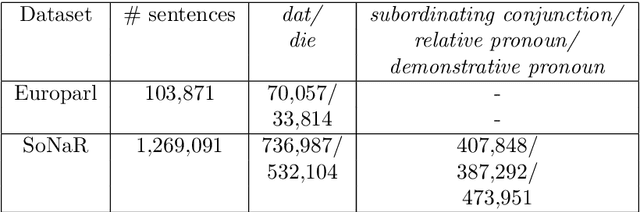
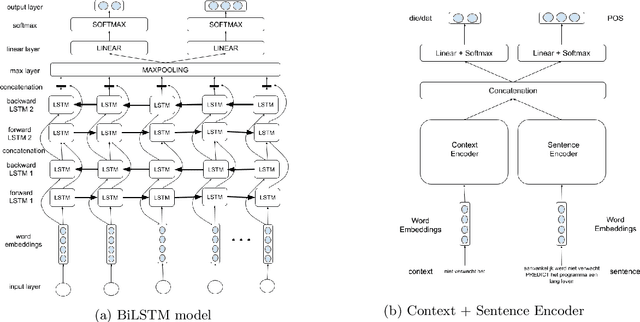
The correct use of Dutch pronouns 'die' and 'dat' is a stumbling block for both native and non-native speakers of Dutch due to the multiplicity of syntactic functions and the dependency on the antecedent's gender and number. Drawing on previous research conducted on neural context-dependent dt-mistake correction models (Heyman et al. 2018), this study constructs the first neural network model for Dutch demonstrative and relative pronoun resolution that specifically focuses on the correction and part-of-speech prediction of these two pronouns. Two separate datasets are built with sentences obtained from, respectively, the Dutch Europarl corpus (Koehn 2015) - which contains the proceedings of the European Parliament from 1996 to the present - and the SoNaR corpus (Oostdijk et al. 2013) - which contains Dutch texts from a variety of domains such as newspapers, blogs and legal texts. Firstly, a binary classification model solely predicts the correct 'die' or 'dat'. The classifier with a bidirectional long short-term memory architecture achieves 84.56% accuracy. Secondly, a multitask classification model simultaneously predicts the correct 'die' or 'dat' and its part-of-speech tag. The model containing a combination of a sentence and context encoder with both a bidirectional long short-term memory architecture results in 88.63% accuracy for die/dat prediction and 87.73% accuracy for part-of-speech prediction. More evenly-balanced data, larger word embeddings, an extra bidirectional long short-term memory layer and integrated part-of-speech knowledge positively affects die/dat prediction performance, while a context encoder architecture raises part-of-speech prediction performance. This study shows promising results and can serve as a starting point for future research on machine learning models for Dutch anaphora resolution.
Temporal Information Extraction by Predicting Relative Time-lines
Aug 28, 2018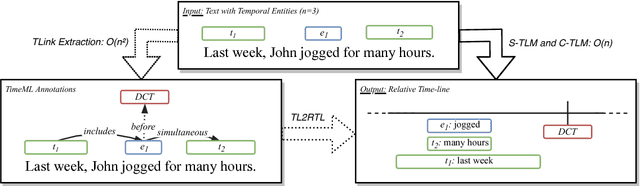
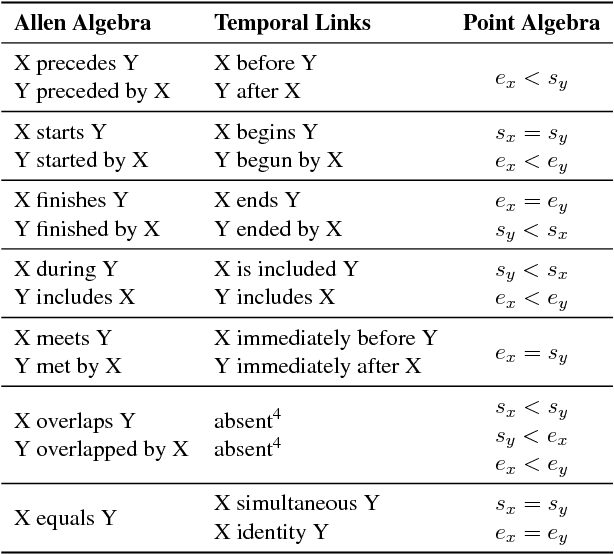
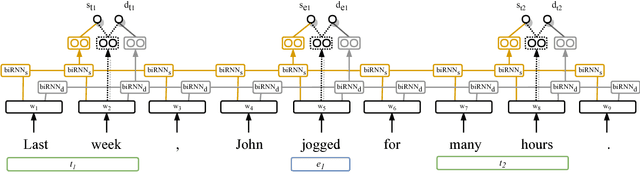

The current leading paradigm for temporal information extraction from text consists of three phases: (1) recognition of events and temporal expressions, (2) recognition of temporal relations among them, and (3) time-line construction from the temporal relations. In contrast to the first two phases, the last phase, time-line construction, received little attention and is the focus of this work. In this paper, we propose a new method to construct a linear time-line from a set of (extracted) temporal relations. But more importantly, we propose a novel paradigm in which we directly predict start and end-points for events from the text, constituting a time-line without going through the intermediate step of prediction of temporal relations as in earlier work. Within this paradigm, we propose two models that predict in linear complexity, and a new training loss using TimeML-style annotations, yielding promising results.
Word-Level Loss Extensions for Neural Temporal Relation Classification
Aug 07, 2018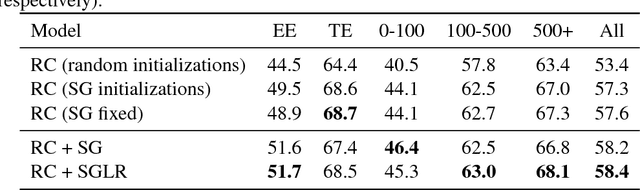
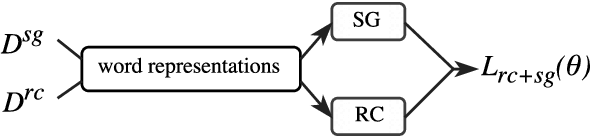
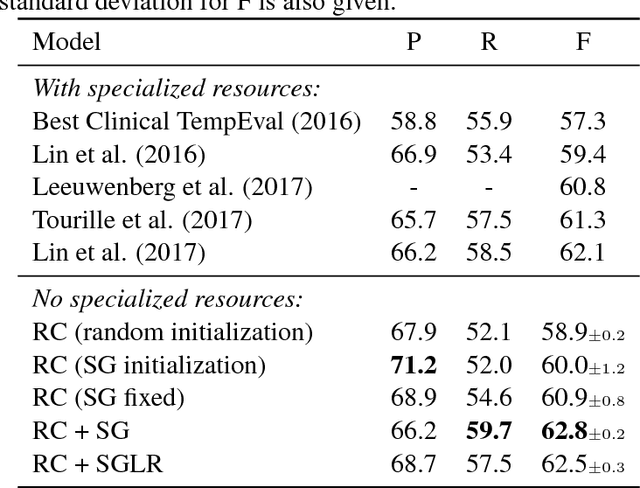
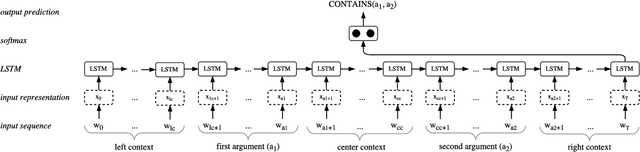
Unsupervised pre-trained word embeddings are used effectively for many tasks in natural language processing to leverage unlabeled textual data. Often these embeddings are either used as initializations or as fixed word representations for task-specific classification models. In this work, we extend our classification model's task loss with an unsupervised auxiliary loss on the word-embedding level of the model. This is to ensure that the learned word representations contain both task-specific features, learned from the supervised loss component, and more general features learned from the unsupervised loss component. We evaluate our approach on the task of temporal relation extraction, in particular, narrative containment relation extraction from clinical records, and show that continued training of the embeddings on the unsupervised objective together with the task objective gives better task-specific embeddings, and results in an improvement over the state of the art on the THYME dataset, using only a general-domain part-of-speech tagger as linguistic resource.