 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-Level Loss Extensions for Neural Temporal Relation Classification
Paper and Code
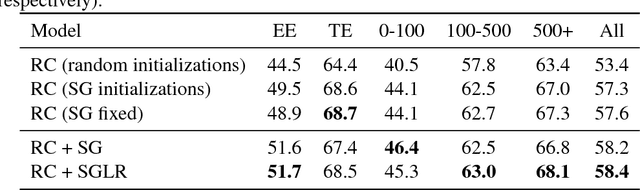
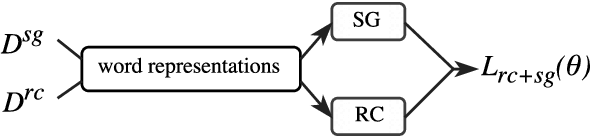
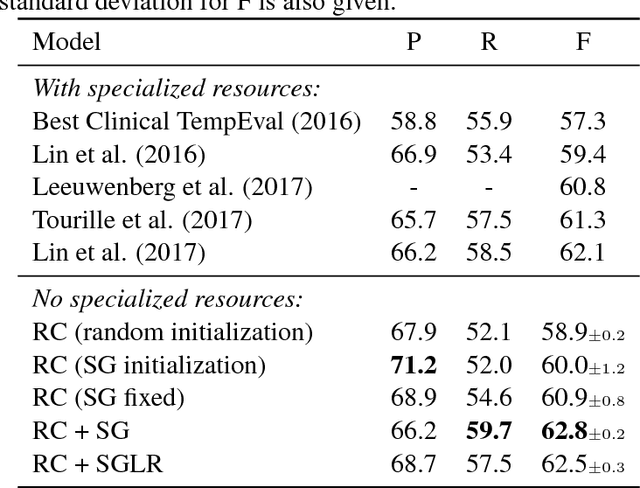
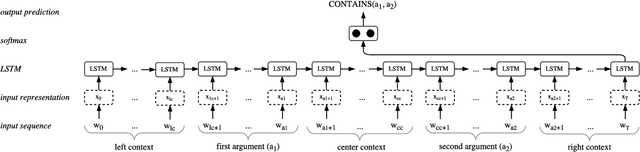
Unsupervised pre-trained word embeddings are used effectively for many tasks in natural language processing to leverage unlabeled textual data. Often these embeddings are either used as initializations or as fixed word representations for task-specific classification models. In this work, we extend our classification model's task loss with an unsupervised auxiliary loss on the word-embedding level of the model. This is to ensure that the learned word representations contain both task-specific features, learned from the supervised loss component, and more general features learned from the unsupervised loss component. We evaluate our approach on the task of temporal relation extraction, in particular, narrative containment relation extraction from clinical records, and show that continued training of the embeddings on the unsupervised objective together with the task objective gives better task-specific embeddings, and results in an improvement over the state of the art on the THYME dataset, using only a general-domain part-of-speech tagger as linguistic resource.