 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Search with Subword TF-IDF
Sep 29, 2022


Multilingual search can be achieved with subword tokenization. The accuracy of traditional TF-IDF approaches depend on manually curated tokenization, stop words and stemming rules, whereas subword TF-IDF (STF-IDF) can offer higher accuracy without such heuristics. Moreover, multilingual support can be incorporated inherently as part of the subword tokenization model training. XQuAD evaluation demonstrates the advantages of STF-IDF: superior information retrieval accuracy of 85.4% for English and over 80% for 10 other languages without any heuristics-based preprocessing. The software to reproduce these results are open-sourced as a part of Text2Text: https://github.com/artitw/text2text
Transfer Learning Robustness in Multi-Class Categorization by Fine-Tuning Pre-Trained Contextualized Language Models
Sep 21, 2019
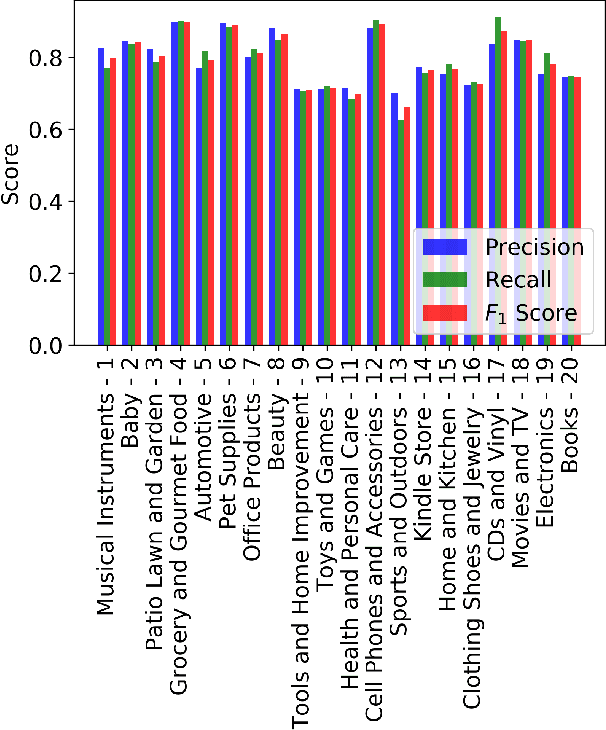


This study compares the effectiveness and robustness of multi-class categorization of Amazon product data using transfer learning on pre-trained contextualized language models. Specifically, we fine-tuned BERT and XLNet, two bidirectional models that have achieved state-of-the-art performance on many natural language tasks and benchmarks, including text classification. While existing classification studies and benchmarks focus on binary targets, with the exception of ordinal ranking tasks, here we examine the robustness of such models as the number of classes grows from 1 to 20. Our experiments demonstrate an approximately linear decrease in performance metrics (i.e., precision, recall, $F_1$ score, and accuracy) with the number of class labels. BERT consistently outperforms XLNet using identical hyperparameters on the entire range of class label quantities for categorizing products based on their textual descriptions. BERT is also more affordable than XLNet in terms of the computational cost (i.e., time and memory) required for training. In all cases studied, the performance degradation rates were estimated to be 1% per additional class label.
Question Generation by Transformers
Sep 14, 2019
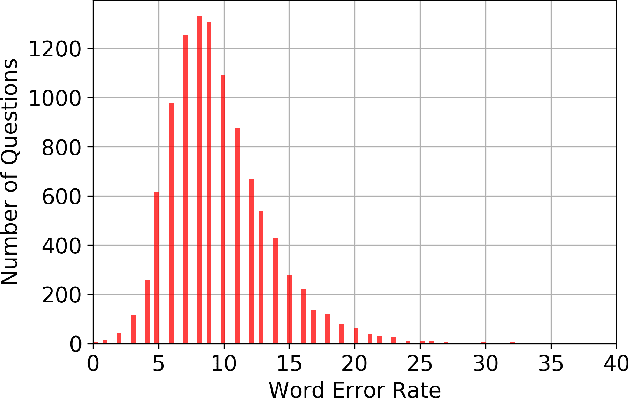
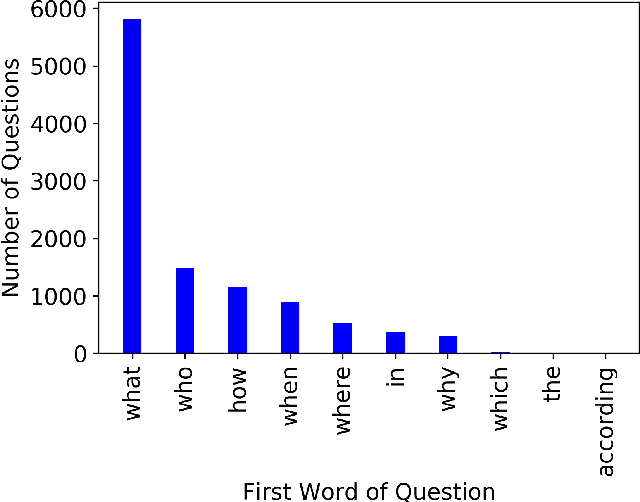

A machine learning model was developed to automatically generate questions from Wikipedia passages using transformers, an attention-based model eschewing the paradigm of existing recurrent neural networks (RNNs). The model was trained on the inverted Stanford Question Answering Dataset (SQuAD), which is a reading comprehension dataset consisting of 100,000+ questions posed by crowdworkers on a set of Wikipedia articles. After training, the question generation model is able to generate simple questions relevant to unseen passages and answers containing an average of 8 words per question. The word error rate (WER) was used as a metric to compare the similarity between SQuAD questions and the model-generated questions. Although the high average WER suggests that the questions generated differ from the original SQuAD questions, the questions generated are mostly grammatically correct and plausible in their own right.
Multi-Label Product Categorization Using Multi-Modal Fusion Models
Jun 30, 2019


In this study, we investigated multi-modal approaches using images, descriptions, and title to categorize e-commerce products on Amazon.com. Specifically, we examined late fusion models, where the modalities are fused at the decision level. Products were each assigned multiple labels, and the hierarchy in the labels were flattened and filtered. For our individual baseline models, we modified a CNN architecture to classify the description and title, and then modified Keras' ResNet-50 to classify the images, achieving F1 scores of 77.0%, 82.7%, and 61.0%, respectively. In comparison, our tri-modal late fusion model can classify products more accurately than single modal models can, improving the F1 score to 88.2%. Each modality complemented the shortcomings of the other modalities, demonstrating that increasing the number of modalities can be an effective method for improving the accuracy of multi-label classification problems.
Attending to Mathematical Language with Transformers
Jan 14, 2019

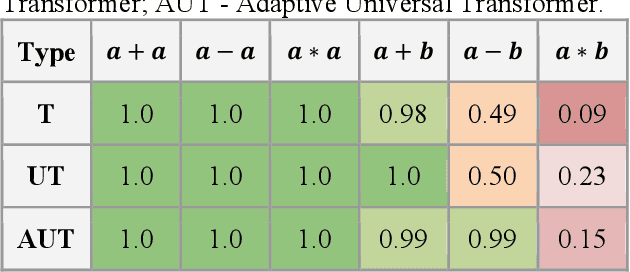

Mathematical expressions were generated, evaluated and used to train neural network models based on the transformer architecture. The expressions and their targets were analyzed as a character-level sequence transduction task in which the encoder and decoder are built on attention mechanisms. Three models were trained to understand and evaluate symbolic variables and expressions in mathematics: (1) the self-attentive and feed-forward transformer without recurrence or convolution, (2) the universal transformer with recurrence, and (3) the adaptive universal transformer with recurrence and adaptive computation time. The models respectively achieved test accuracies as high as 76.1%, 78.8% and 84.9% in evaluating the expressions to match the target values. For the cases inferred incorrectly, the results differed from the targets by only one or two characters. The models notably learned to add, subtract and multiply both positive and negative decimal numbers of variable digits assigned to symbolic variables.
A Collaborative Approach to Angel and Venture Capital Investment Recommendations
Jul 26, 2018


Matrix factorization was used to generate investment recommendations for investors. An iterative conjugate gradient method was used to optimize the regularized squared-error loss function. The number of latent factors, number of iterations, and regularization values were explored. Overfitting can be addressed by either early stopping or regularization parameter tuning. The model achieved the highest average prediction accuracy of 13.3%. With a similar model, the same dataset was used to generate investor recommendations for companies undergoing fundraising, which achieved highest prediction accuracy of 11.1%.
Comparing heterogeneous entities using artificial neural networks of trainable weighted structural components and machine-learned activation functions
Jan 09, 2018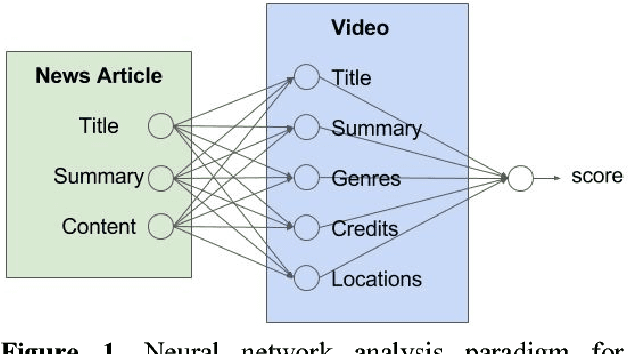
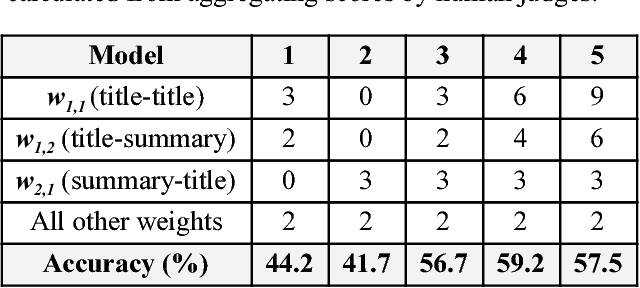
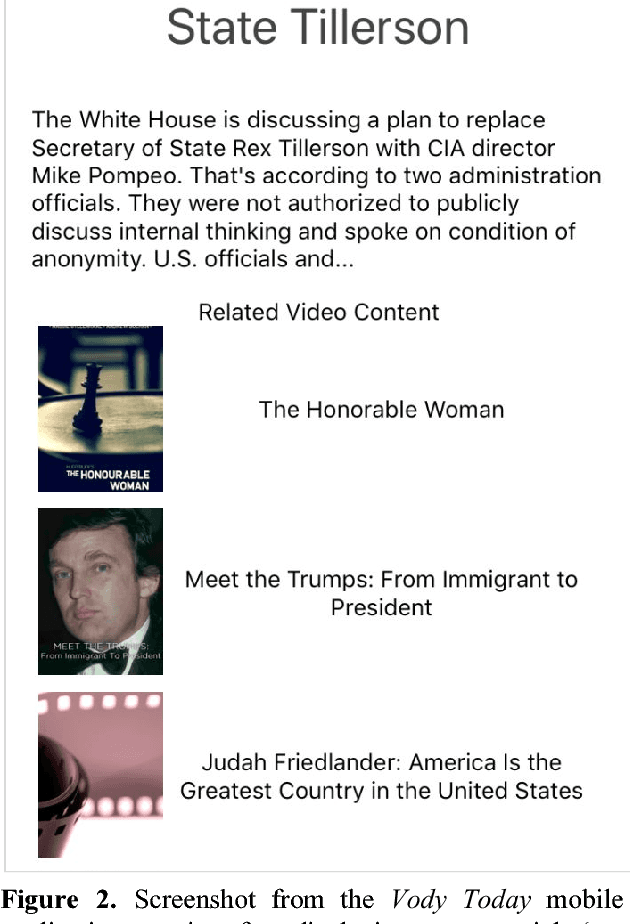
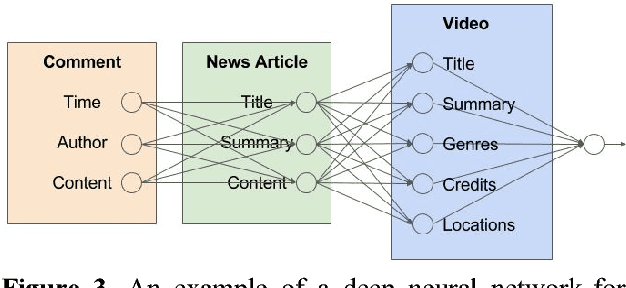
To compare entities of differing types and structural components, the artificial neural network paradigm was used to cross-compare structural components between heterogeneous documents. Trainable weighted structural components were input into machine-learned activation functions of the neurons. The model was used for matching news articles and videos, where the inputs and activation functions respectively consisted of term vectors and cosine similarity measures between the weighted structural components. The model was tested with different weights, achieving as high as 59.2% accuracy for matching videos to news articles. A mobile application user interface for recommending related videos for news articles was developed to demonstrate consumer value, including its potential usefulness for cross-selling products from unrelated categories.
Churn analysis using deep convolutional neural networks and autoencoders
Apr 18, 2016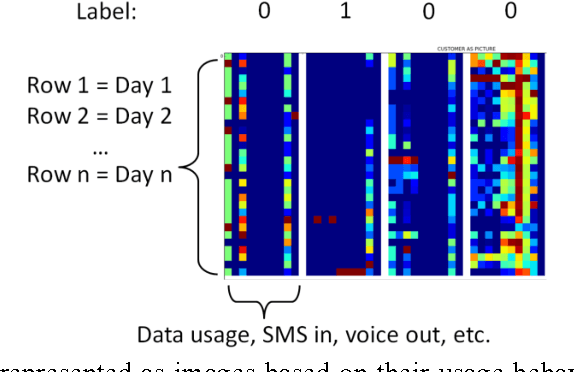
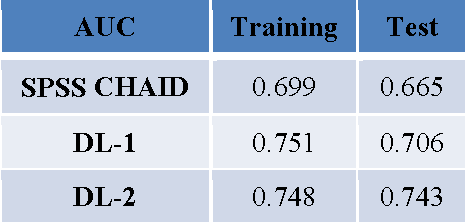
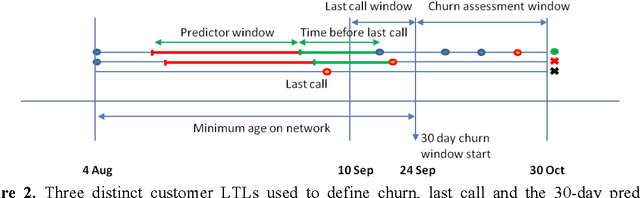
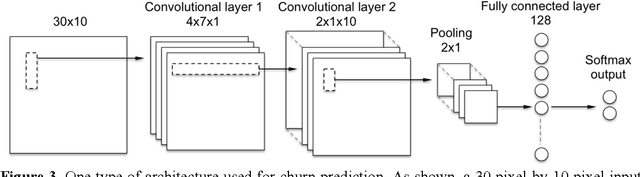
Customer temporal behavioral data was represented as images in order to perform churn prediction by leveraging deep learning architectures prominent in image classification. Supervised learning was performed on labeled data of over 6 million customers using deep convolutional neural networks, which achieved an AUC of 0.743 on the test dataset using no more than 12 temporal features for each customer. Unsupervised learning was conducted using autoencoders to better understand the reasons for customer churn. Images that maximally activate the hidden units of an autoencoder trained with churned customers reveal ample opportunities for action to be taken to prevent churn among strong data, no voice users.