 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Generation by Transformers
Sep 14, 2019
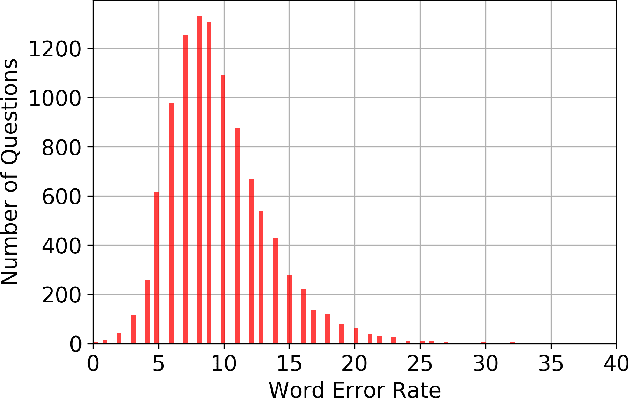
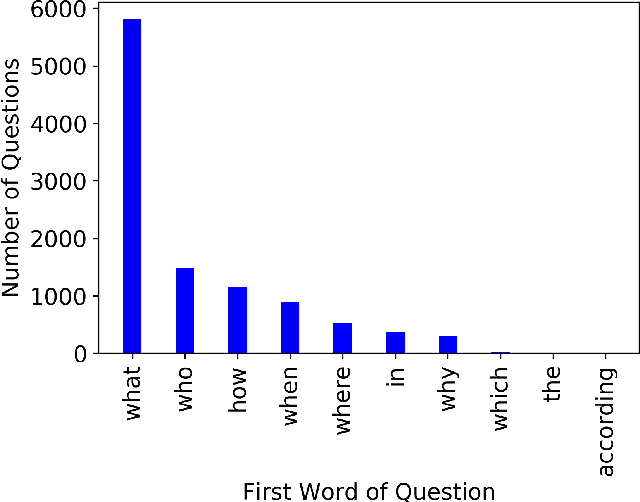

A machine learning model was developed to automatically generate questions from Wikipedia passages using transformers, an attention-based model eschewing the paradigm of existing recurrent neural networks (RNNs). The model was trained on the inverted Stanford Question Answering Dataset (SQuAD), which is a reading comprehension dataset consisting of 100,000+ questions posed by crowdworkers on a set of Wikipedia articles. After training, the question generation model is able to generate simple questions relevant to unseen passages and answers containing an average of 8 words per question. The word error rate (WER) was used as a metric to compare the similarity between SQuAD questions and the model-generated questions. Although the high average WER suggests that the questions generated differ from the original SQuAD questions, the questions generated are mostly grammatically correct and plausible in their own right.
Comparing heterogeneous entities using artificial neural networks of trainable weighted structural components and machine-learned activation functions
Jan 09, 2018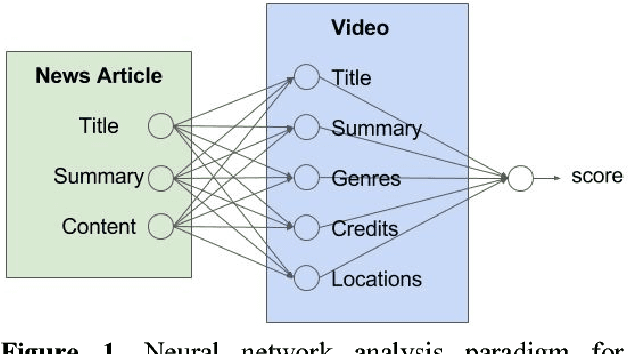
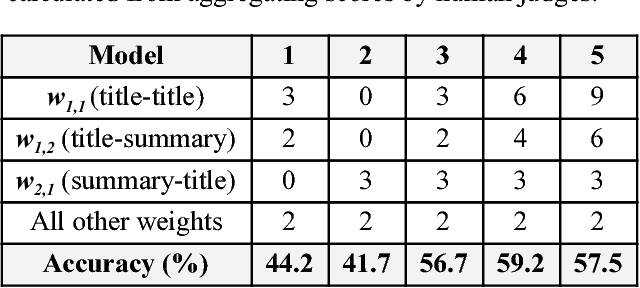
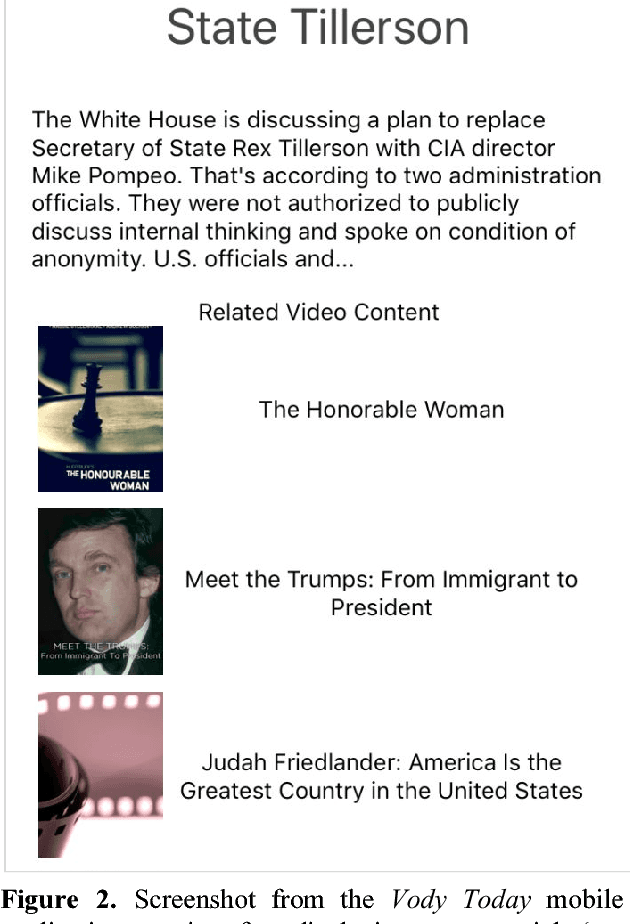
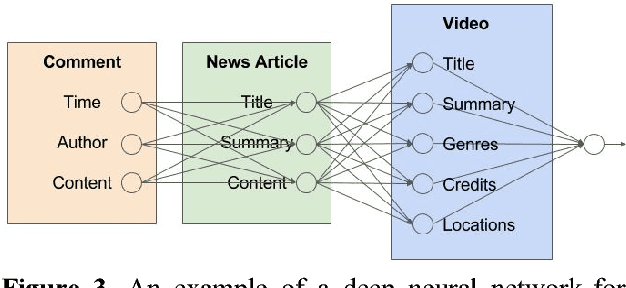
To compare entities of differing types and structural components, the artificial neural network paradigm was used to cross-compare structural components between heterogeneous documents. Trainable weighted structural components were input into machine-learned activation functions of the neurons. The model was used for matching news articles and videos, where the inputs and activation functions respectively consisted of term vectors and cosine similarity measures between the weighted structural components. The model was tested with different weights, achieving as high as 59.2% accuracy for matching videos to news articles. A mobile application user interface for recommending related videos for news articles was developed to demonstrate consumer value, including its potential usefulness for cross-selling products from unrelated categories.