Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional neural networks pretrained on large face recognition datasets for emotion classification from video
Nov 13, 2017
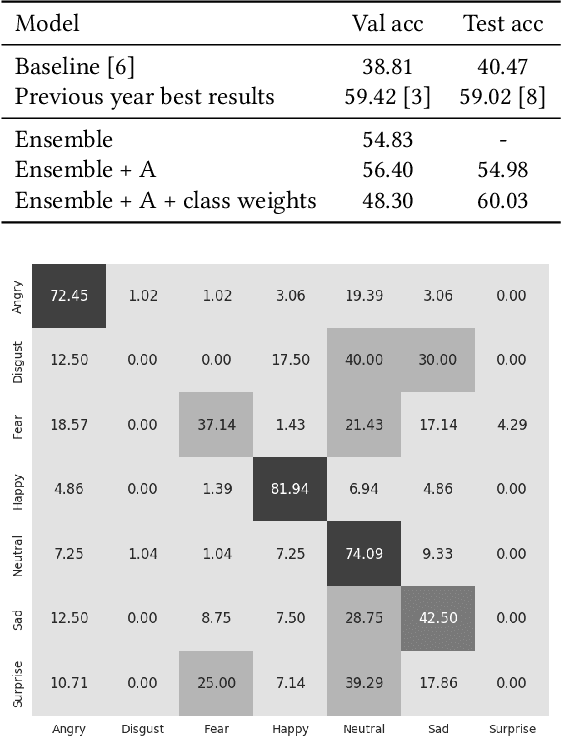
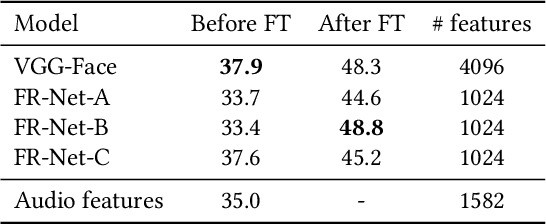

In this paper we describe a solution to our entry for the emotion recognition challenge EmotiW 2017. We propose an ensemble of several models, which capture spatial and audio features from videos. Spatial features are captured by convolutional neural networks, pretrained on large face recognition datasets. We show that usage of strong industry-level face recognition networks increases the accuracy of emotion recognition. Using our ensemble we improve on the previous best result on the test set by about 1 %, achieving a 60.03 % classification accuracy without any use of visual temporal information.
* 4 pages
Via