 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster learning of deep stacked autoencoders on multi-core systems using synchronized layer-wise pre-training
Mar 09, 2016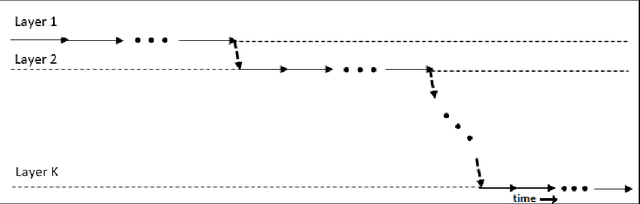

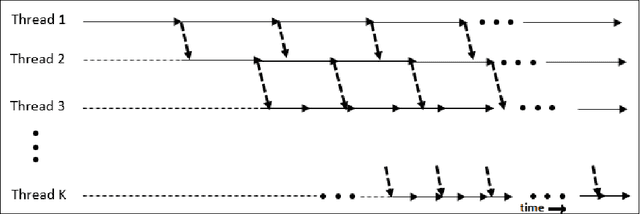

Deep neural networks are capable of modelling highly non-linear functions by capturing different levels of abstraction of data hierarchically. While training deep networks, first the system is initialized near a good optimum by greedy layer-wise unsupervised pre-training. However, with burgeoning data and increasing dimensions of the architecture, the time complexity of this approach becomes enormous. Also, greedy pre-training of the layers often turns detrimental by over-training a layer causing it to lose harmony with the rest of the network. In this paper a synchronized parallel algorithm for pre-training deep networks on multi-core machines has been proposed. Different layers are trained by parallel threads running on different cores with regular synchronization. Thus the pre-training process becomes faster and chances of over-training are reduced. This is experimentally validated using a stacked autoencoder for dimensionality reduction of MNIST handwritten digit database. The proposed algorithm achieved 26\% speed-up compared to greedy layer-wise pre-training for achieving the same reconstruction accuracy substantiating its potential as an alternative.