 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery for Causal Bandits utilizing Separating Sets
Sep 16, 2020


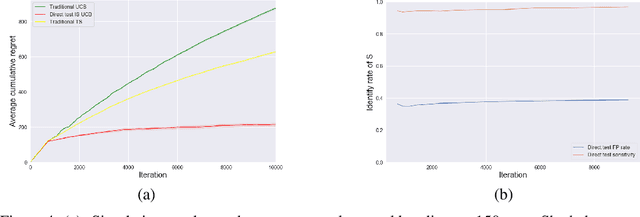
The Causal Bandit is a variant of the classic Bandit problem where an agent must identify the best action in a sequential decision-making process, where the reward distribution of the actions displays a non-trivial dependence structure that is governed by a causal model. All methods proposed thus far in the literature rely on exact prior knowledge of the causal model to obtain improved estimators for the reward. We formulate a new causal bandit algorithm that is the first to no longer rely on explicit prior causal knowledge and instead uses the output of causal discovery algorithms. This algorithm relies on a new estimator based on separating sets, a causal structure already known in causal discovery literature. We show that given a separating set, this estimator is unbiased, and has lower variance compared to the sample mean. We derive a concentration bound and construct a UCB-type algorithm based on this bound, as well as a Thompson sampling variant. We compare our algorithms with traditional bandit algorithms on simulation data. On these problems, our algorithms show a significant boost in performance.