 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIngredient Extraction from Text in the Recipe Domain
Apr 18, 2022
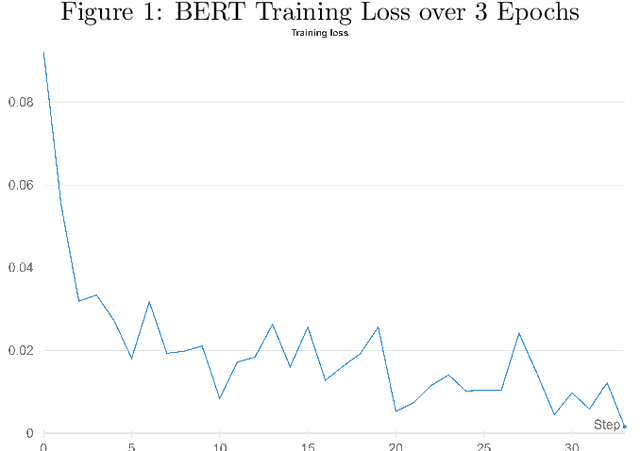
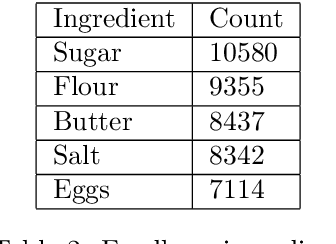

In recent years, there has been an increase in the number of devices with virtual assistants (e.g: Siri, Google Home, Alexa) in our living rooms and kitchens. As a result of this, these devices receive several queries about recipes. All these queries will contain terms relating to a "recipe-domain" i.e: they will contain dish-names, ingredients, cooking times, dietary preferences etc. Extracting these recipe-relevant aspects from the query thus becomes important when it comes to addressing the user's information need. Our project focuses on extracting ingredients from such plain-text user utterances. Our best performing model was a fine-tuned BERT which achieved an F1-score of $95.01$. We have released all our code in a GitHub repository.
Drink bleach or do what now? Covid-HeRA: A dataset for risk-informed health decision making in the presence of COVID19 misinformation
Oct 17, 2020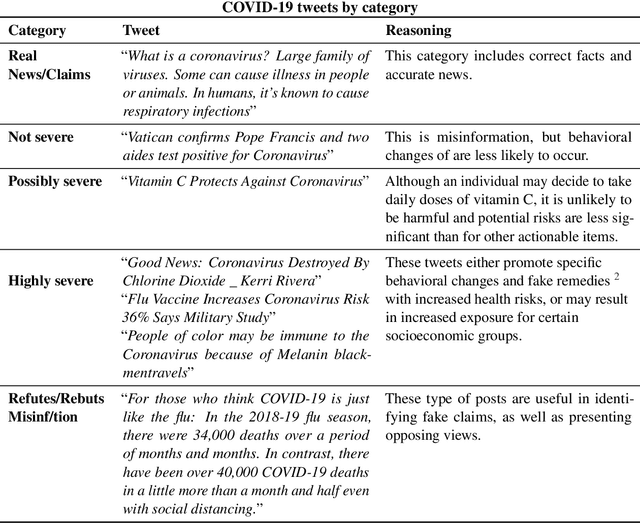



Given the wide spread of inaccurate medical advice related to the 2019 coronavirus pandemic (COVID-19), such as fake remedies, treatments and prevention suggestions, misinformation detection has emerged as an open problem of high importance and interest for the NLP community. To combat potential harm of COVID19-related misinformation, we release Covid-HeRA, a dataset for health risk assessment of COVID-19-related social media posts. More specifically, we study the severity of each misinformation story, i.e., how harmful a message believed by the audience can be and what type of signals can be used to discover high malicious fake news and detect refuted claims. We present a detailed analysis, evaluate several simple and advanced classification models, and conclude with our experimental analysis that presents open challenges and future directions.