 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Zen: Efficient GUI Understanding and Precise Grounding With A Novel Multimodal LLM
May 24, 2024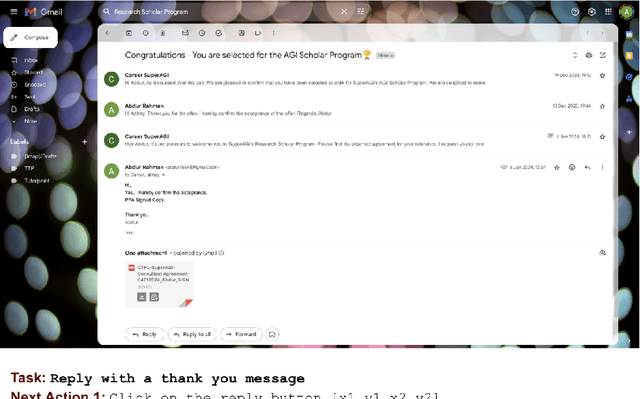



In the rapidly evolving landscape of AI research and application, Multimodal Large Language Models (MLLMs) have emerged as a transformative force, adept at interpreting and integrating information from diverse modalities such as text, images, and Graphical User Interfaces (GUIs). Despite these advancements, the nuanced interaction and understanding of GUIs pose a significant challenge, limiting the potential of existing models to enhance automation levels. To bridge this gap, this paper presents V-Zen, an innovative Multimodal Large Language Model (MLLM) meticulously crafted to revolutionise the domain of GUI understanding and grounding. Equipped with dual-resolution image encoders, V-Zen establishes new benchmarks in efficient grounding and next-action prediction, thereby laying the groundwork for self-operating computer systems. Complementing V-Zen is the GUIDE dataset, an extensive collection of real-world GUI elements and task-based sequences, serving as a catalyst for specialised fine-tuning. The successful integration of V-Zen and GUIDE marks the dawn of a new era in multimodal AI research, opening the door to intelligent, autonomous computing experiences. This paper extends an invitation to the research community to join this exciting journey, shaping the future of GUI automation. In the spirit of open science, our code, data, and model will be made publicly available, paving the way for multimodal dialogue scenarios with intricate and precise interactions.
AUTONODE: A Neuro-Graphic Self-Learnable Engine for Cognitive GUI Automation
Mar 15, 2024



In recent advancements within the domain of Large Language Models (LLMs), there has been a notable emergence of agents capable of addressing Robotic Process Automation (RPA) challenges through enhanced cognitive capabilities and sophisticated reasoning. This development heralds a new era of scalability and human-like adaptability in goal attainment. In this context, we introduce AUTONODE (Autonomous User-interface Transformation through Online Neuro-graphic Operations and Deep Exploration). AUTONODE employs advanced neuro-graphical techniques to facilitate autonomous navigation and task execution on web interfaces, thereby obviating the necessity for predefined scripts or manual intervention. Our engine empowers agents to comprehend and implement complex workflows, adapting to dynamic web environments with unparalleled efficiency. Our methodology synergizes cognitive functionalities with robotic automation, endowing AUTONODE with the ability to learn from experience. We have integrated an exploratory module, DoRA (Discovery and mapping Operation for graph Retrieval Agent), which is instrumental in constructing a knowledge graph that the engine utilizes to optimize its actions and achieve objectives with minimal supervision. The versatility and efficacy of AUTONODE are demonstrated through a series of experiments, highlighting its proficiency in managing a diverse array of web-based tasks, ranging from data extraction to transaction processing.