 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperCoder2.0: Technical Report on Exploring the feasibility of LLMs as Autonomous Programmer
Sep 17, 2024

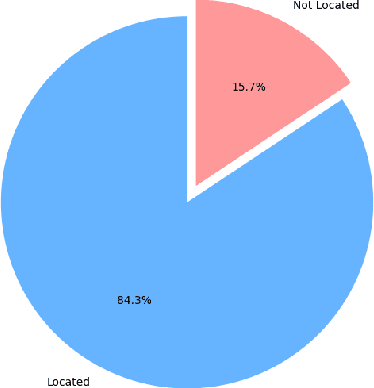

We present SuperCoder2.0, an advanced autonomous system designed to enhance software development through artificial intelligence. The system combines an AI-native development approach with intelligent agents to enable fully autonomous coding. Key focus areas include a retry mechanism with error output traceback, comprehensive code rewriting and replacement using Abstract Syntax Tree (ast) parsing to minimize linting issues, code embedding technique for retrieval-augmented generation, and a focus on localizing methods for problem-solving rather than identifying specific line numbers. The methodology employs a three-step hierarchical search space reduction approach for code base navigation and bug localization:utilizing Retrieval Augmented Generation (RAG) and a Repository File Level Map to identify candidate files, (2) narrowing down to the most relevant files using a File Level Schematic Map, and (3) extracting 'relevant locations' within these files. Code editing is performed through a two-part module comprising CodeGeneration and CodeEditing, which generates multiple solutions at different temperature values and replaces entire methods or classes to maintain code integrity. A feedback loop executes repository-level test cases to validate and refine solutions. Experiments conducted on the SWE-bench Lite dataset demonstrate SuperCoder2.0's effectiveness, achieving correct file localization in 84.33% of cases within the top 5 candidates and successfully resolving 34% of test instances. This performance places SuperCoder2.0 fourth globally on the SWE-bench leaderboard. The system's ability to handle diverse repositories and problem types highlights its potential as a versatile tool for autonomous software development. Future work will focus on refining the code editing process and exploring advanced embedding models for improved natural language to code mapping.
V-Zen: Efficient GUI Understanding and Precise Grounding With A Novel Multimodal LLM
May 24, 2024In the rapidly evolving landscape of AI research and application, Multimodal Large Language Models (MLLMs) have emerged as a transformative force, adept at interpreting and integrating information from diverse modalities such as text, images, and Graphical User Interfaces (GUIs). Despite these advancements, the nuanced interaction and understanding of GUIs pose a significant challenge, limiting the potential of existing models to enhance automation levels. To bridge this gap, this paper presents V-Zen, an innovative Multimodal Large Language Model (MLLM) meticulously crafted to revolutionise the domain of GUI understanding and grounding. Equipped with dual-resolution image encoders, V-Zen establishes new benchmarks in efficient grounding and next-action prediction, thereby laying the groundwork for self-operating computer systems. Complementing V-Zen is the GUIDE dataset, an extensive collection of real-world GUI elements and task-based sequences, serving as a catalyst for specialised fine-tuning. The successful integration of V-Zen and GUIDE marks the dawn of a new era in multimodal AI research, opening the door to intelligent, autonomous computing experiences. This paper extends an invitation to the research community to join this exciting journey, shaping the future of GUI automation. In the spirit of open science, our code, data, and model will be made publicly available, paving the way for multimodal dialogue scenarios with intricate and precise interactions.