 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA temporal deep learning framework for calibration of low-cost air quality sensors
Apr 23, 2026Low-cost air quality sensors (LCS) provide a practical alternative to expensive regulatory-grade instruments, making dense urban monitoring networks possible. Yet their adoption is limited by calibration challenges, including sensor drift, environmental cross-sensitivity, and variability in performance from device to device. This work presents a deep learning framework for calibrating LCS measurements of PM$_{2.5}$, PM$_{10}$, and NO$_2$ using a Long Short-Term Memory (LSTM) network, trained on co-located reference data from the OxAria network in Oxford, UK. Unlike the Random Forest (RF) baseline, which treats each observation independently, the proposed approach captures temporal dependencies and delayed environmental effects through sequence-based learning, achieving higher $R^2$ values across training, validation, and test sets for all three pollutants. A feature set is constructed combining time-lagged parameters, harmonic encodings, and interaction terms to improve generalization on unseen temporal windows. Validation of unseen calibrated values against the Equivalence Spreadsheet Tool 3.1 demonstrates regulatory compliance with expanded uncertainties of 22.11% for NO$_2$, 12.42% for PM$_{10}$, and 9.1% for PM$_{2.5}$.
Hybrid machine learning models based on physical patterns to accelerate CFD simulations: a short guide on autoregressive models
Apr 09, 2025



Accurate modeling of the complex dynamics of fluid flows is a fundamental challenge in computational physics and engineering. This study presents an innovative integration of High-Order Singular Value Decomposition (HOSVD) with Long Short-Term Memory (LSTM) architectures to address the complexities of reduced-order modeling (ROM) in fluid dynamics. HOSVD improves the dimensionality reduction process by preserving multidimensional structures, surpassing the limitations of Singular Value Decomposition (SVD). The methodology is tested across numerical and experimental data sets, including two- and three-dimensional (2D and 3D) cylinder wake flows, spanning both laminar and turbulent regimes. The emphasis is also on exploring how the depth and complexity of LSTM architectures contribute to improving predictive performance. Simpler architectures with a single dense layer effectively capture the periodic dynamics, demonstrating the network's ability to model non-linearities and chaotic dynamics. The addition of extra layers provides higher accuracy at minimal computational cost. These additional layers enable the network to expand its representational capacity, improving the prediction accuracy and reliability. The results demonstrate that HOSVD outperforms SVD in all tested scenarios, as evidenced by using different error metrics. Efficient mode truncation by HOSVD-based models enables the capture of complex temporal patterns, offering reliable predictions even in challenging, noise-influenced data sets. The findings underscore the adaptability and robustness of HOSVD-LSTM architectures, offering a scalable framework for modeling fluid dynamics.
Deep Learning-Based Robust Multi-Object Tracking via Fusion of mmWave Radar and Camera Sensors
Jul 10, 2024Autonomous driving holds great promise in addressing traffic safety concerns by leveraging artificial intelligence and sensor technology. Multi-Object Tracking plays a critical role in ensuring safer and more efficient navigation through complex traffic scenarios. This paper presents a novel deep learning-based method that integrates radar and camera data to enhance the accuracy and robustness of Multi-Object Tracking in autonomous driving systems. The proposed method leverages a Bi-directional Long Short-Term Memory network to incorporate long-term temporal information and improve motion prediction. An appearance feature model inspired by FaceNet is used to establish associations between objects across different frames, ensuring consistent tracking. A tri-output mechanism is employed, consisting of individual outputs for radar and camera sensors and a fusion output, to provide robustness against sensor failures and produce accurate tracking results. Through extensive evaluations of real-world datasets, our approach demonstrates remarkable improvements in tracking accuracy, ensuring reliable performance even in low-visibility scenarios.
3D Radar and Camera Co-Calibration: A Flexible and Accurate Method for Target-based Extrinsic Calibration
Jul 28, 2023



Advances in autonomous driving are inseparable from sensor fusion. Heterogeneous sensors are widely used for sensor fusion due to their complementary properties, with radar and camera being the most equipped sensors. Intrinsic and extrinsic calibration are essential steps in sensor fusion. The extrinsic calibration, independent of the sensor's own parameters, and performed after the sensors are installed, greatly determines the accuracy of sensor fusion. Many target-based methods require cumbersome operating procedures and well-designed experimental conditions, making them extremely challenging. To this end, we propose a flexible, easy-to-reproduce and accurate method for extrinsic calibration of 3D radar and camera. The proposed method does not require a specially designed calibration environment, and instead places a single corner reflector (CR) on the ground to iteratively collect radar and camera data simultaneously using Robot Operating System (ROS), and obtain radar-camera point correspondences based on their timestamps, and then use these point correspondences as input to solve the perspective-n-point (PnP) problem, and finally get the extrinsic calibration matrix. Also, RANSAC is used for robustness and the Levenberg-Marquardt (LM) nonlinear optimization algorithm is used for accuracy. Multiple controlled environment experiments as well as real-world experiments demonstrate the efficiency and accuracy (AED error is 15.31 pixels and Acc up to 89\%) of the proposed method.
mmPose-NLP: A Natural Language Processing Approach to Precise Skeletal Pose Estimation using mmWave Radars
Jul 21, 2021
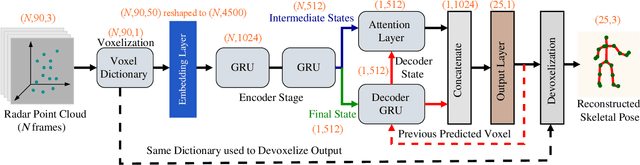
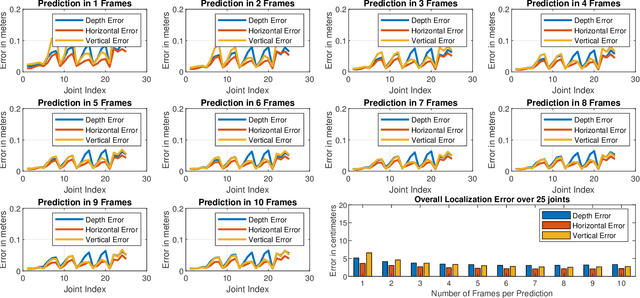
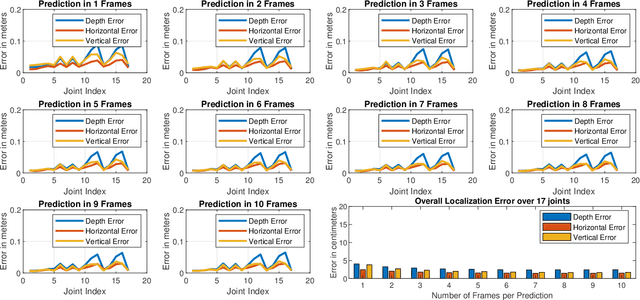
In this paper we presented mmPose-NLP, a novel Natural Language Processing (NLP) inspired Sequence-to-Sequence (Seq2Seq) skeletal key-point estimator using millimeter-wave (mmWave) radar data. To the best of the author's knowledge, this is the first method to precisely estimate upto 25 skeletal key-points using mmWave radar data alone. Skeletal pose estimation is critical in several applications ranging from autonomous vehicles, traffic monitoring, patient monitoring, gait analysis, to defense security forensics, and aid both preventative and actionable decision making. The use of mmWave radars for this task, over traditionally employed optical sensors, provide several advantages, primarily its operational robustness to scene lighting and adverse weather conditions, where optical sensor performance degrade significantly. The mmWave radar point-cloud (PCL) data is first voxelized (analogous to tokenization in NLP) and $N$ frames of the voxelized radar data (analogous to a text paragraph in NLP) is subjected to the proposed mmPose-NLP architecture, where the voxel indices of the 25 skeletal key-points (analogous to keyword extraction in NLP) are predicted. The voxel indices are converted back to real world 3-D coordinates using the voxel dictionary used during the tokenization process. Mean Absolute Error (MAE) metrics were used to measure the accuracy of the proposed system against the ground truth, with the proposed mmPose-NLP offering <3 cm localization errors in the depth, horizontal and vertical axes. The effect of the number of input frames vs performance/accuracy was also studied for N = {1,2,..,10}. A comprehensive methodology, results, discussions and limitations are presented in this paper. All the source codes and results are made available on GitHub for furthering research and development in this critical yet emerging domain of skeletal key-point estimation using mmWave radars.
mmFall: Fall Detection using 4D MmWave Radar and Variational Recurrent Autoencoder
Mar 28, 2020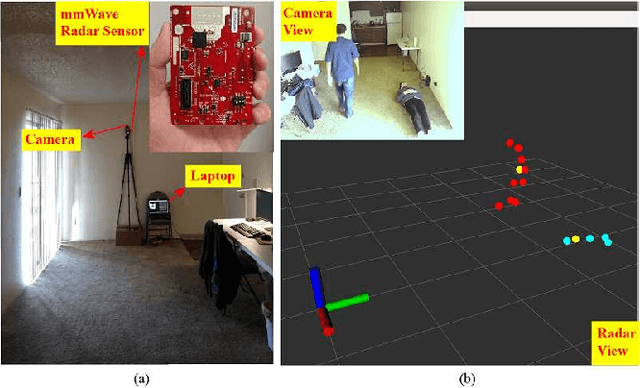
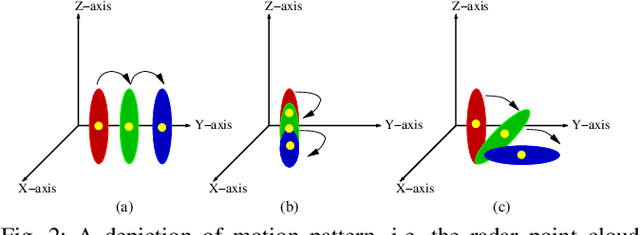
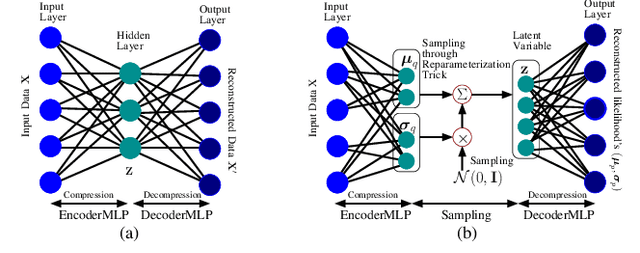
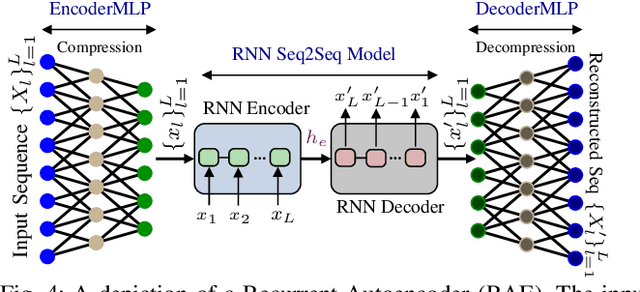
In this paper we propose mmFall - a novel fall detection system, which comprises of (i) the emerging millimeter-wave (mmWave) radar sensor to collect the human body's point cloud along with the body centroid, and (ii) a variational recurrent autoencoder (VRAE) to compute the anomaly level of the body motion based on the acquired point cloud. A fall is claimed to have occurred when the spike in anomaly level and the drop in centroid height occur simultaneously. The mmWave radar sensor provides several advantages, such as privacycompliance and high-sensitivity to motion, over the traditional sensing modalities. However, (i) randomness in radar point cloud data and (ii) difficulties in fall collection/labeling in the traditional supervised fall detection approaches are the two main challenges. To overcome the randomness in radar data, the proposed VRAE uses variational inference, a probabilistic approach rather than the traditional deterministic approach, to infer the posterior probability of the body's latent motion state at each frame, followed by a recurrent neural network (RNN) to learn the temporal features of the motion over multiple frames. Moreover, to circumvent the difficulties in fall data collection/labeling, the VRAE is built upon an autoencoder architecture in a semi-supervised approach, and trained on only normal activities of daily living (ADL) such that in the inference stage the VRAE will generate a spike in the anomaly level once an abnormal motion, such as fall, occurs. During the experiment, we implemented the VRAE along with two other baselines, and tested on the dataset collected in an apartment. The receiver operating characteristic (ROC) curve indicates that our proposed model outperforms the other two baselines, and achieves 98% detection out of 50 falls at the expense of just 2 false alarms.