 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Session Threats in AI Agents: Benchmark, Evaluation, and Algorithms
Apr 22, 2026AI-agent guardrails are memoryless: each message is judged in isolation, so an adversary who spreads a single attack across dozens of sessions slips past every session-bound detector because only the aggregate carries the payload. We make three contributions to cross-session threat detection. (1) Dataset. CSTM-Bench is 26 executable attack taxonomies classified by kill-chain stage and cross-session operation (accumulate, compose, launder, inject_on_reader), each bound to one of seven identity anchors that ground-truth "violation" as a policy predicate, plus matched Benign-pristine and Benign-hard confounders. Released on Hugging Face as intrinsec-ai/cstm-bench with two 54-scenario splits: dilution (compositional) and cross_session (12 isolation-invisible scenarios produced by a closed-loop rewriter that softens surface phrasing while preserving cross-session artefacts). (2) Measurement. Framing cross-session detection as an information bottleneck to a downstream correlator LLM, we find that a session-bound judge and a Full-Log Correlator concatenating every prompt into one long-context call both lose roughly half their attack recall moving from dilution to cross_session, well inside any frontier context window. Scope: 54 scenarios per shard, one correlator family (Anthropic Claude), no prompt optimisation; we release it to motivate larger, multi-provider datasets. (3) Algorithm and metric. A bounded-memory Coreset Memory Reader retaining highest-signal fragments at $K=50$ is the only reader whose recall survives both shards. Because ranker reshuffles break KV-cache prefix reuse, we promote $\mathrm{CSR\_prefix}$ (ordered prefix stability, LLM-free) to a first-class metric and fuse it with detection into $\mathrm{CSTM} = 0.7 F_1(\mathrm{CSDA@action}, \mathrm{precision}) + 0.3 \mathrm{CSR\_prefix}$, benchmarking rankers on a single Pareto of recall versus serving stability.
Language Alignment via Nash-learning and Adaptive feedback
Jun 22, 2024
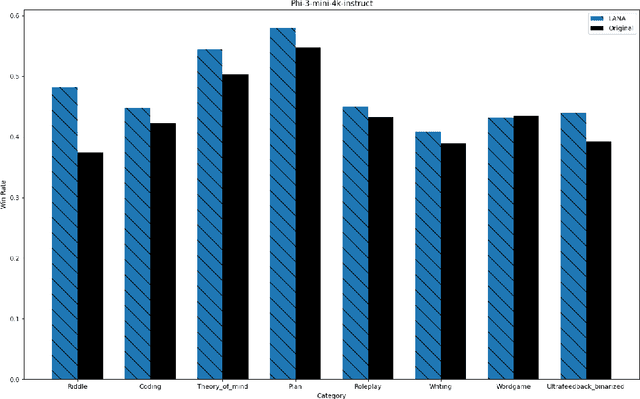

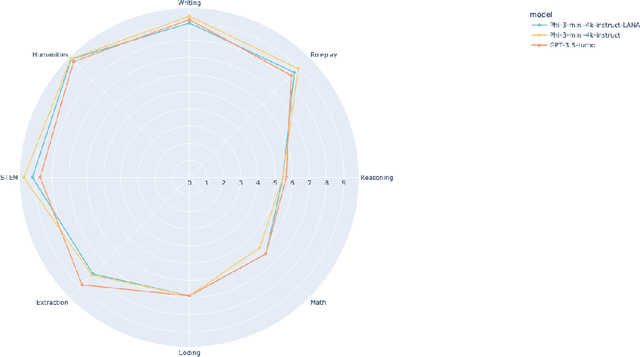
Recent research has shown the potential of Nash Learning via Human Feedback for large language model alignment by incorporating the notion of a preference model in a minimax game setup. We take this idea further by casting the alignment as a mirror descent algorithm against the adaptive feedback of an improved opponent, thereby removing the need for learning a preference model or the existence of an annotated dataset altogether. The resulting algorithm, which we refer to as Language Alignment via Nash-learning and Adaptive feedback (LANA), is capable of self-alignment without the need for a human-annotated preference dataset. We support this statement with various experiments and mathematical discussion.
Differentiable Neural Computers with Memory Demon
Nov 05, 2022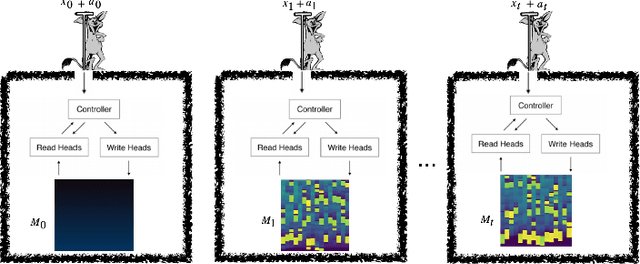



A Differentiable Neural Computer (DNC) is a neural network with an external memory which allows for iterative content modification via read, write and delete operations. We show that information theoretic properties of the memory contents play an important role in the performance of such architectures. We introduce a novel concept of memory demon to DNC architectures which modifies the memory contents implicitly via additive input encoding. The goal of the memory demon is to maximize the expected sum of mutual information of the consecutive external memory contents.
Correlated Adversarial Imitation Learning
Feb 16, 2020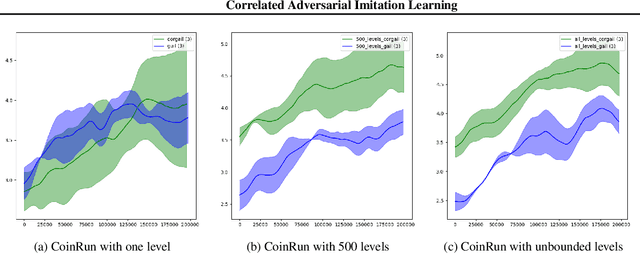
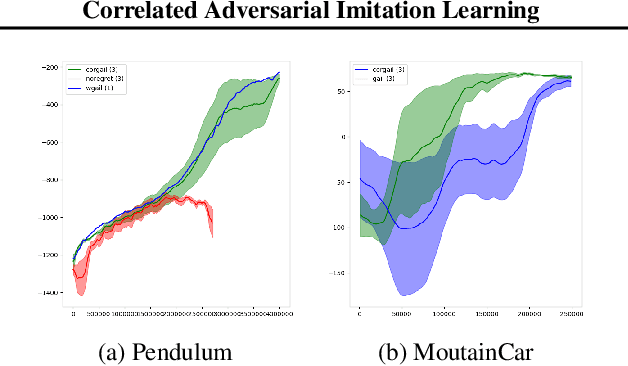

A novel imitation learning algorithm is introduced by applying a game-theoretic notion of correlated equilibrium to the generative adversarial imitation learning. This imitation learning algorithm is equipped with queues of discriminators and agents, in contrast with the classical approach, where there are single discriminator and single agent. The achievement of a correlated equilibrium is due to a mediating neural architecture, which augments the observations that are being seen by queues of discriminators and agents. At every step of the training, the mediator network computes feedback using the rewards of discriminators and agents, to augment the next observations accordingly. By interacting in the game, it steers the training dynamic towards more suitable regions. The resulting imitation learning provides three important benefits. First, it makes adaptability and transferability of the learned model to new environments straightforward. Second, it is suitable for imitating a mixture of state-action trajectories. Third, it avoids the difficulties of non-convex optimization faced by the discriminator in the generative adversarial type architectures.
Hierarchical Soft Actor-Critic: Adversarial Exploration via Mutual Information Optimization
Jun 17, 2019
We describe a novel extension of soft actor-critics for hierarchical Deep Q-Networks (HDQN) architectures using mutual information metric. The proposed extension provides a suitable framework for encouraging explorations in such hierarchical networks. A natural utilization of this framework is an adversarial setting, where meta-controller and controller play minimax over the mutual information objective but cooperate on maximizing expected rewards.
Fuzzy Hashing as Perturbation-Consistent Adversarial Kernel Embedding
Dec 17, 2018


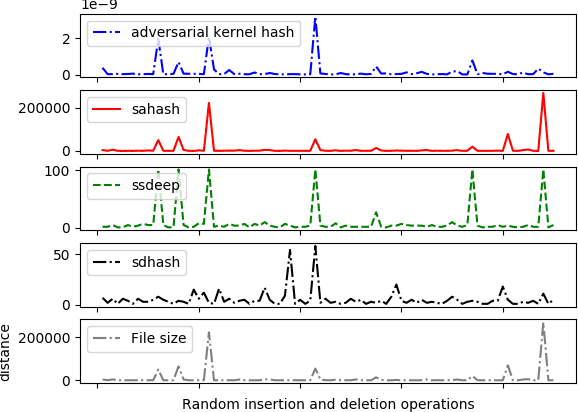
Measuring the similarity of two files is an important task in malware analysis, with fuzzy hash functions being a popular approach. Traditional fuzzy hash functions are data agnostic: they do not learn from a particular dataset how to determine similarity; their behavior is fixed across all datasets. In this paper, we demonstrate that fuzzy hash functions can be learned in a novel minimax training framework and that these learned fuzzy hash functions outperform traditional fuzzy hash functions at the file similarity task for Portable Executable files. In our approach, hash digests can be extracted from the kernel embeddings of two kernel networks, trained in a minimax framework, where the roles of players during training (i.e adversary versus generator) alternate along with the input data. We refer to this new minimax architecture as perturbation-consistent. The similarity score for a pair of files is the utility of the minimax game in equilibrium. Our experiments show that learned fuzzy hash functions generalize well, capable of determining that two files are similar even when one of those files was generated using insertion and deletion operations.