Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Alignment via Nash-learning and Adaptive feedback
Paper and Code
Jun 22, 2024
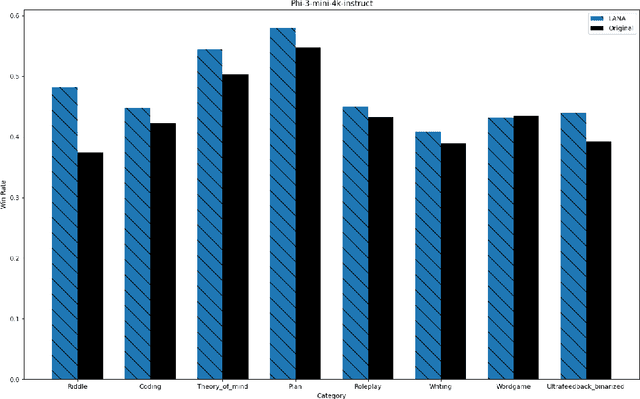

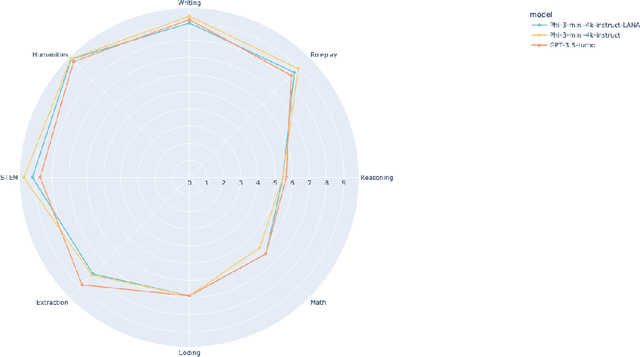
Recent research has shown the potential of Nash Learning via Human Feedback for large language model alignment by incorporating the notion of a preference model in a minimax game setup. We take this idea further by casting the alignment as a mirror descent algorithm against the adaptive feedback of an improved opponent, thereby removing the need for learning a preference model or the existence of an annotated dataset altogether. The resulting algorithm, which we refer to as Language Alignment via Nash-learning and Adaptive feedback (LANA), is capable of self-alignment without the need for a human-annotated preference dataset. We support this statement with various experiments and mathematical discussion.
* Accepted at ICML 2024 Workshop on Models of Human Feedback for AI
Alignment, Vienna, Austria
View paper on