 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoBandit: Efficient Prototype Selection via Multi-Armed Bandits
Oct 09, 2022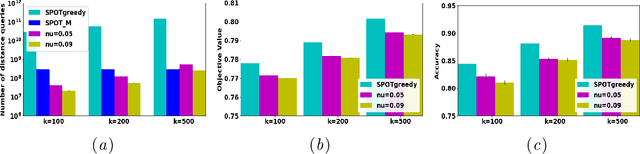
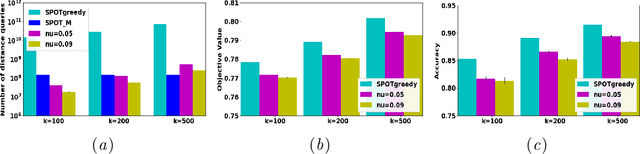


In this work, we propose a multi-armed bandit based framework for identifying a compact set of informative data instances (i.e., the prototypes) that best represents a given target set. Prototypical examples of a given dataset offer interpretable insights into the underlying data distribution and assist in example-based reasoning, thereby influencing every sphere of human decision making. A key challenge is the large-scale setting, in which similarity comparison between pairs of data points needs to be done for almost all possible pairs. We propose to overcome this limitation by employing stochastic greedy search on the space of prototypical examples and multi-armed bandit approach for reducing the number of similarity comparisons. A salient feature of the proposed approach is that the total number of similarity comparisons needed is independent of the size of the target set. Empirically, we observe that our proposed approach, ProtoBandit, reduces the total number of similarity computation calls by several orders of magnitudes (100-1000 times) while obtaining solutions similar in quality to those from existing state-of-the-art approaches.
Regret Minimisation in Multi-Armed Bandits Using Bounded Arm Memory
Jan 24, 2019
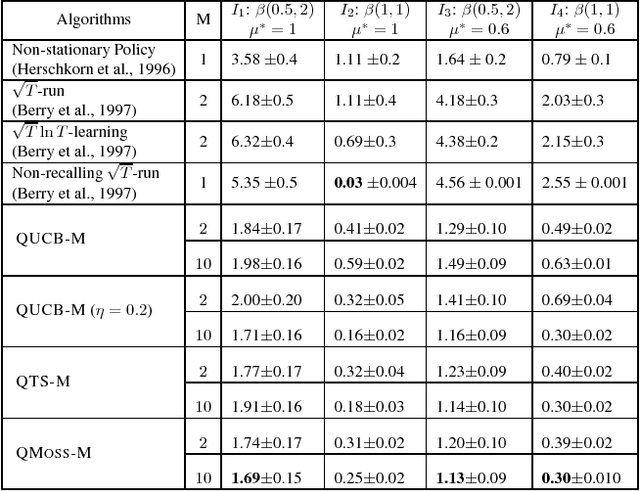
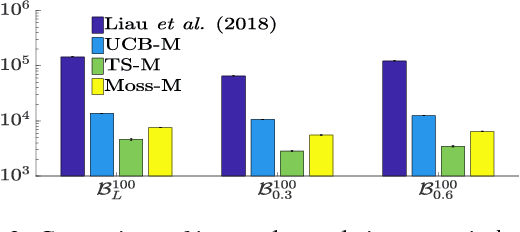

In this paper, we propose a constant word (RAM model) algorithm for regret minimisation for both finite and infinite Stochastic Multi-Armed Bandit (MAB) instances. Most of the existing regret minimisation algorithms need to remember the statistics of all the arms they encounter. This may become a problem for the cases where the number of available words of memory is limited. Designing an efficient regret minimisation algorithm that uses a constant number of words has long been interesting to the community. Some early attempts consider the number of arms to be infinite, and require the reward distribution of the arms to belong to some particular family. Recently, for finitely many-armed bandits an explore-then-commit based algorithm~\citep{Liau+PSY:2018} seems to escape such assumption. However, due to the underlying PAC-based elimination their method incurs a high regret. We present a conceptually simple, and efficient algorithm that needs to remember statistics of at most $M$ arms, and for any $K$-armed finite bandit instance it enjoys a $O(KM +K^{1.5}\sqrt{T\log (T/MK)}/M)$ upper-bound on regret. We extend it to achieve sub-linear \textit{quantile-regret}~\citep{RoyChaudhuri+K:2018} and empirically verify the efficiency of our algorithm via experiments.
PAC Identification of Many Good Arms in Stochastic Multi-Armed Bandits
Jan 24, 2019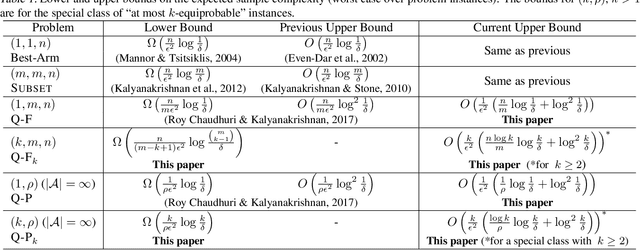
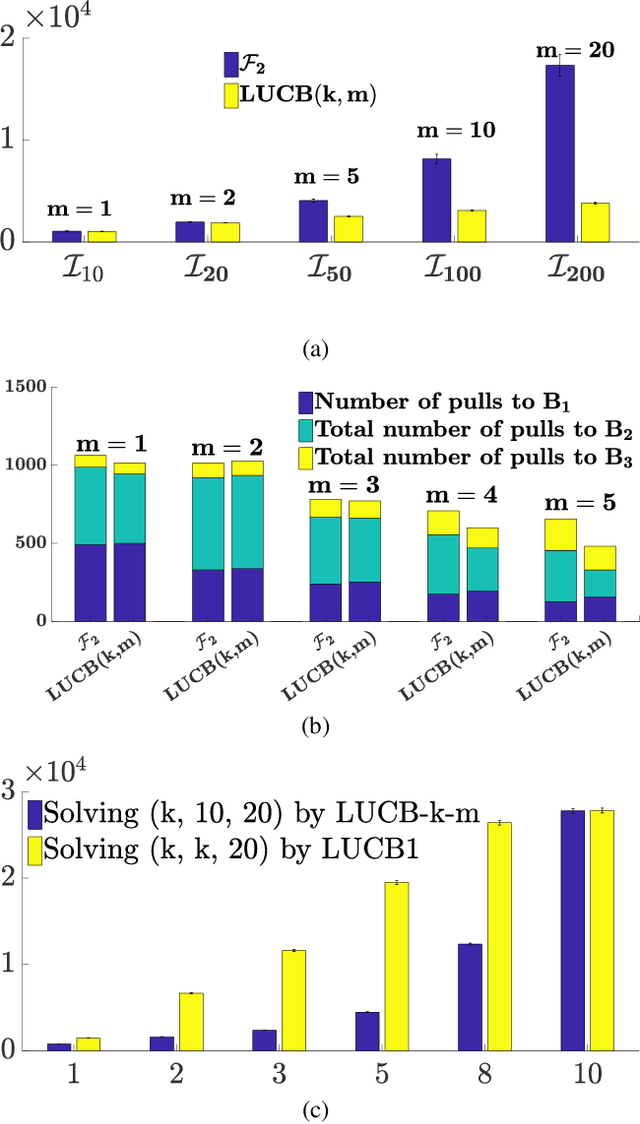
We consider the problem of identifying any $k$ out of the best $m$ arms in an $n$-armed stochastic multi-armed bandit. Framed in the PAC setting, this particular problem generalises both the problem of `best subset selection' and that of selecting `one out of the best m' arms [arcsk 2017]. In applications such as crowd-sourcing and drug-designing, identifying a single good solution is often not sufficient. Moreover, finding the best subset might be hard due to the presence of many indistinguishably close solutions. Our generalisation of identifying exactly $k$ arms out of the best $m$, where $1 \leq k \leq m$, serves as a more effective alternative. We present a lower bound on the worst-case sample complexity for general $k$, and a fully sequential PAC algorithm, \GLUCB, which is more sample-efficient on easy instances. Also, extending our analysis to infinite-armed bandits, we present a PAC algorithm that is independent of $n$, which identifies an arm from the best $\rho$ fraction of arms using at most an additive poly-log number of samples than compared to the lower bound, thereby improving over [arcsk 2017] and [Aziz+AKA:2018]. The problem of identifying $k > 1$ distinct arms from the best $\rho$ fraction is not always well-defined; for a special class of this problem, we present lower and upper bounds. Finally, through a reduction, we establish a relation between upper bounds for the `one out of the best $\rho$' problem for infinite instances and the `one out of the best $m$' problem for finite instances. We conjecture that it is more efficient to solve `small' finite instances using the latter formulation, rather than going through the former.