 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Shape of Overthinking: Backtracking Bursts in Long Reasoning Traces
May 27, 2026Reasoning models often generate long traces in which useful self-correction and unproductive revision are hard to distinguish. We study this distinction through backtracking dynamics: local reconsideration, retraction, or re-derivation inside long-form reasoning traces. On 6{,}000 Qwen3-8B AIME traces, we annotate segment-level backtrack severity and analyze event timing, normalized depth, and local burst structure. We find that early isolated repair is often compatible with correct reasoning, whereas incorrect traces more often show moderate-to-severe backtracks that persist and cluster late. Cross-corpus checks show the same qualitative asymmetry across additional model/domain pairs. Filtering analyses instantiate the signal as a prefix-causal selective early-exit policy: at shallow and intermediate depths, burst-aware filtering outperforms fixed length-based filtering while using only prefix-available features. Moderate length cutoffs remain strong completed-trace baselines, but burst-aware control provides a deployable mechanism for separating recoverable repair from likely instability.
Geometry-Aware Decoding with Wasserstein-Regularized Truncation and Mass Penalties for Large Language Models
Feb 10, 2026Large language models (LLMs) must balance diversity and creativity against logical coherence in open-ended generation. Existing truncation-based samplers are effective but largely heuristic, relying mainly on probability mass and entropy while ignoring semantic geometry of the token space. We present Top-W, a geometry-aware truncation rule that uses Wasserstein distance-defined over token-embedding geometry-to keep the cropped distribution close to the original, while explicitly balancing retained probability mass against the entropy of the kept set. Our theory yields a simple closed-form structure for the fixed-potential subset update: depending on the mass-entropy trade-off, the optimal crop either collapses to a single token or takes the form of a one-dimensional prefix that can be found efficiently with a linear scan. We implement Top-W using efficient geometry-based potentials (nearest-set or k-NN) and pair it with an alternating decoding routine that keeps the standard truncation-and-sampling interface unchanged. Extensive experiments on four benchmarks (GSM8K, GPQA, AlpacaEval, and MT-Bench) across three instruction-tuned models show that Top-W consistently outperforms prior state-of-the-art decoding approaches achieving up to 33.7% improvement. Moreover, we find that Top-W not only improves accuracy-focused performance, but also boosts creativity under judge-based open-ended evaluation.
LLMs Are Not Intelligent Thinkers: Introducing Mathematical Topic Tree Benchmark for Comprehensive Evaluation of LLMs
Jun 07, 2024Large language models (LLMs) demonstrate impressive capabilities in mathematical reasoning. However, despite these achievements, current evaluations are mostly limited to specific mathematical topics, and it remains unclear whether LLMs are genuinely engaging in reasoning. To address these gaps, we present the Mathematical Topics Tree (MaTT) benchmark, a challenging and structured benchmark that offers 1,958 questions across a wide array of mathematical subjects, each paired with a detailed hierarchical chain of topics. Upon assessing different LLMs using the MaTT benchmark, we find that the most advanced model, GPT-4, achieved a mere 54\% accuracy in a multiple-choice scenario. Interestingly, even when employing Chain-of-Thought prompting, we observe mostly no notable improvement. Moreover, LLMs accuracy dramatically reduced by up to 24.2 percentage point when the questions were presented without providing choices. Further detailed analysis of the LLMs' performance across a range of topics showed significant discrepancy even for closely related subtopics within the same general mathematical area. In an effort to pinpoint the reasons behind LLMs performances, we conducted a manual evaluation of the completeness and correctness of the explanations generated by GPT-4 when choices were available. Surprisingly, we find that in only 53.3\% of the instances where the model provided a correct answer, the accompanying explanations were deemed complete and accurate, i.e., the model engaged in genuine reasoning.
Tree-wise Distribution Sensitive hashing: Efficient Maximum likelihood Classification by joint dimensionality reduction in known probabilistic settings
May 11, 2019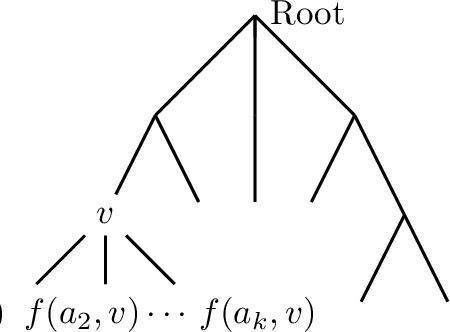
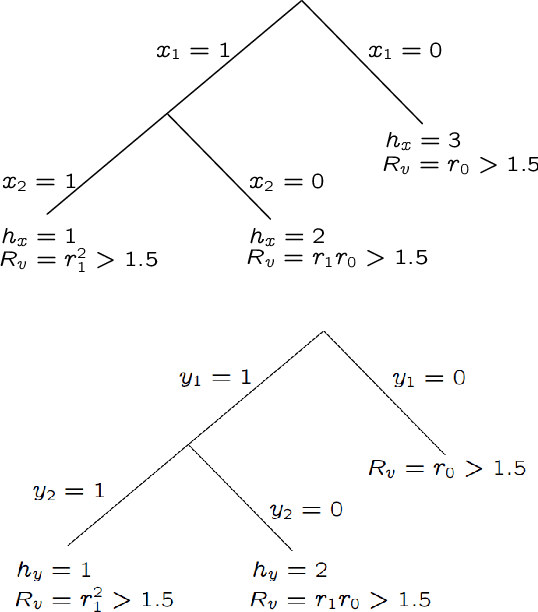
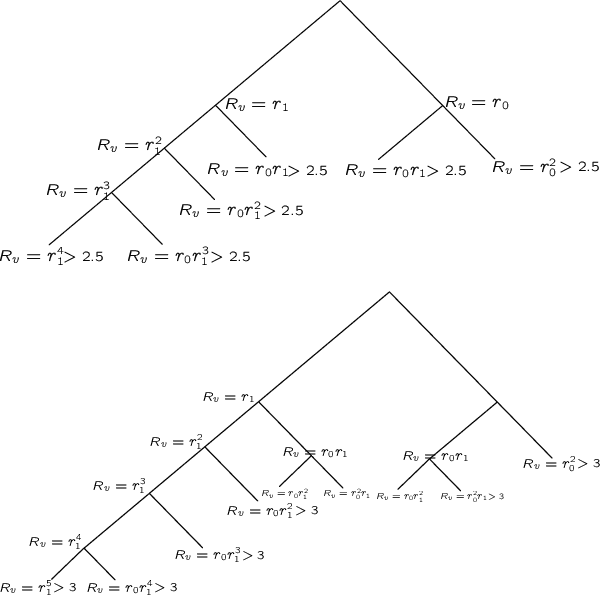
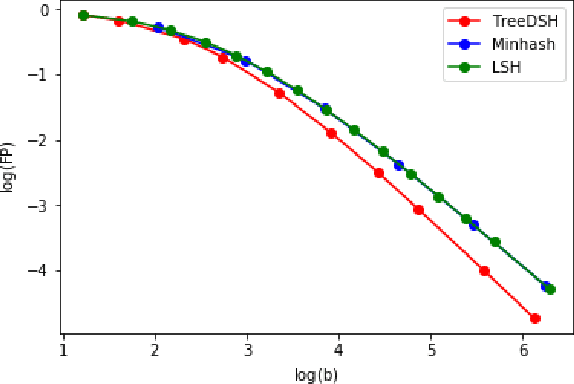
We consider the problem of maximum likelihood classification of a high dimensional data point y to billions of classes $x_1,...,x_N$, where the conditional probability p(y|x) is known. In the most general case, the complexity of the brute-force method for this classification grows linearly, O(N), with the number of classes N. Efficient multiclass classification methods have been introduced to solve this problem with logarithmic complexity. However, these methods suffer from the curse of dimensionality, i.e., in large dimensions their complexity approaches $O(N)$ per query data point. In the special case where the conditional probability distribution $p(y|x)$ is a Gaussian centered at x, i.e., $p(y|x) \propto N (x,\sigma)$, the maximum likelihood classification reduces to the nearest neighbor search with the Euclidean norm. Sublinear methods based on locality sensitive hashing (LSH) have been introduced to solve an approximate version of the nearest neighbor search for high dimensional data. Inspired by these advances, here we introduce distribution sensitive hashing (DSH) to solve an approximate version of the maximum likelihood classification problem through joint dimensionality reduction. In the case of discrete probability distributions, we design TreeDSH, a universal family of distribution sensitive hashes based on the decision trees, and show that their complexity grow sub-linearly. Theory and simulation presented in this paper demonstrate that TreeDSH is more efficient than LSH-hamming and Min-Hashing schemes. Finally, we apply TreeDSH to the problem of peptide identification from mass spectrometry data.