 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSmart: An Auto Updating Federated Learning Optimization Mechanism
Sep 16, 2020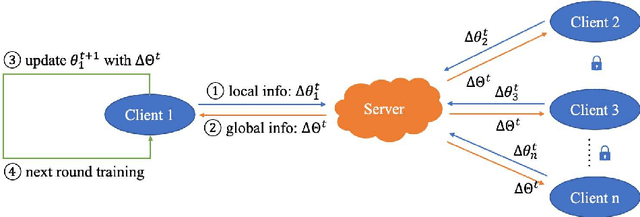
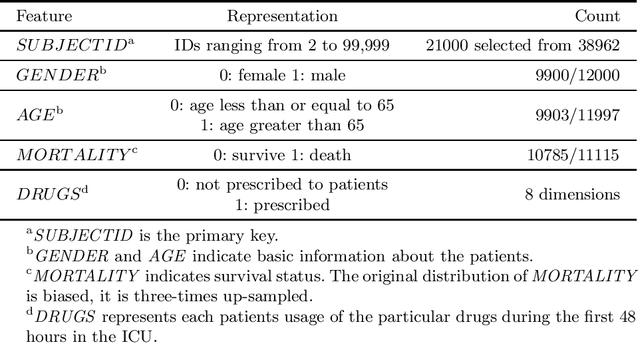
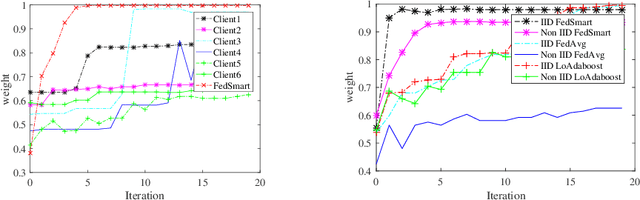
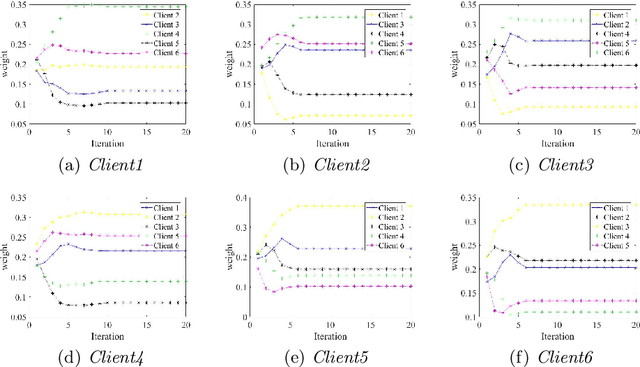
Federated learning has made an important contribution to data privacy-preserving. Many previous works are based on the assumption that the data are independently identically distributed (IID). As a result, the model performance on non-identically independently distributed (non-IID) data is beyond expectation, which is the concrete situation. Some existing methods of ensuring the model robustness on non-IID data, like the data-sharing strategy or pretraining, may lead to privacy leaking. In addition, there exist some participants who try to poison the model with low-quality data. In this paper, a performance-based parameter return method for optimization is introduced, we term it FederatedSmart (FedSmart). It optimizes different model for each client through sharing global gradients, and it extracts the data from each client as a local validation set, and the accuracy that model achieves in round t determines the weights of the next round. The experiment results show that FedSmart enables the participants to allocate a greater weight to the ones with similar data distribution.