 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Speech Perception in Noise: Can Large Language Models Paraphrase to Improve It?
Aug 07, 2024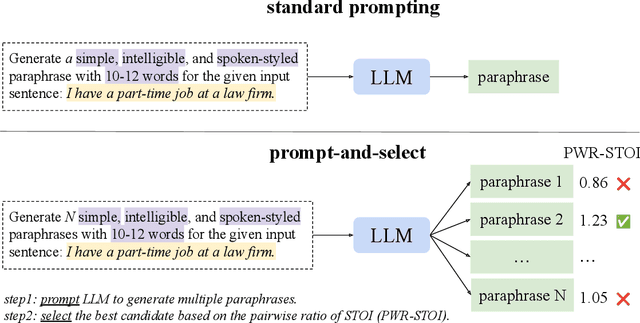



Large Language Models (LLMs) can generate text by transferring style attributes like formality resulting in formal or informal text. However, instructing LLMs to generate text that when spoken, is more intelligible in an acoustically difficult environment, is an under-explored topic. We conduct the first study to evaluate LLMs on a novel task of generating acoustically intelligible paraphrases for better human speech perception in noise. Our experiments in English demonstrated that with standard prompting, LLMs struggle to control the non-textual attribute, i.e., acoustic intelligibility, while efficiently capturing the desired textual attributes like semantic equivalence. To remedy this issue, we propose a simple prompting approach, prompt-and-select, which generates paraphrases by decoupling the desired textual and non-textual attributes in the text generation pipeline. Our approach resulted in a 40% relative improvement in human speech perception, by paraphrasing utterances that are highly distorted in a listening condition with babble noise at a signal-to-noise ratio (SNR) -5 dB. This study reveals the limitation of LLMs in capturing non-textual attributes, and our proposed method showcases the potential of using LLMs for better human speech perception in noise.
A Data-Driven Investigation of Noise-Adaptive Utterance Generation with Linguistic Modification
Oct 19, 2022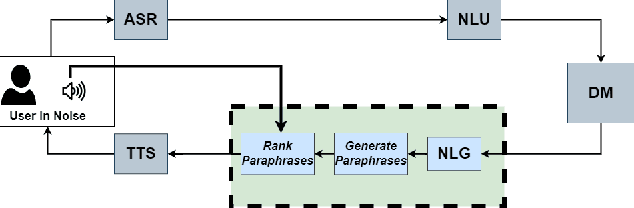
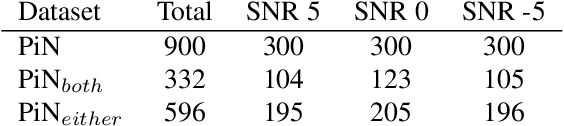
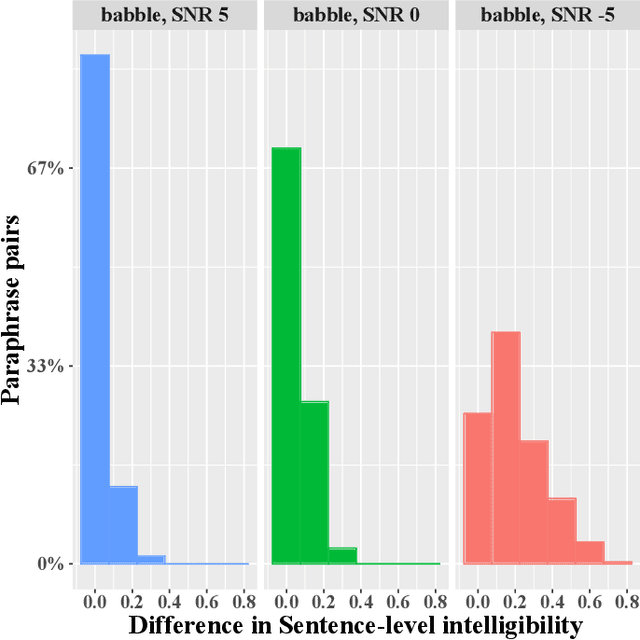
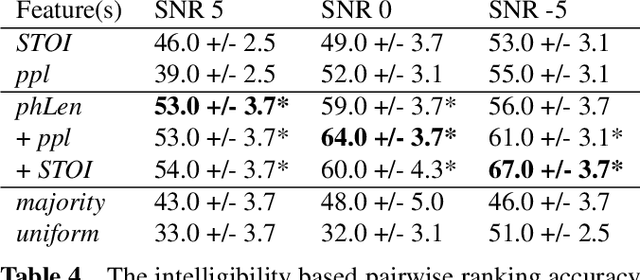
In noisy environments, speech can be hard to understand for humans. Spoken dialog systems can help to enhance the intelligibility of their output, either by modifying the speech synthesis (e.g., imitate Lombard speech) or by optimizing the language generation. We here focus on the second type of approach, by which an intended message is realized with words that are more intelligible in a specific noisy environment. By conducting a speech perception experiment, we created a dataset of 900 paraphrases in babble noise, perceived by native English speakers with normal hearing. We find that careful selection of paraphrases can improve intelligibility by 33% at SNR -5 dB. Our analysis of the data shows that the intelligibility differences between paraphrases are mainly driven by noise-robust acoustic cues. Furthermore, we propose an intelligibility-aware paraphrase ranking model, which outperforms baseline models with a relative improvement of 31.37% at SNR -5 dB.
Exploring the Potential of Lexical Paraphrases for Mitigating Noise-Induced Comprehension Errors
Jul 18, 2021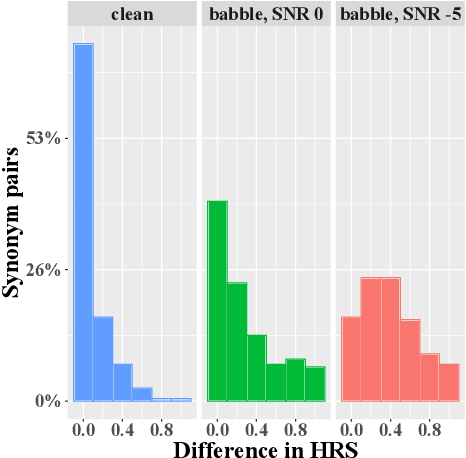
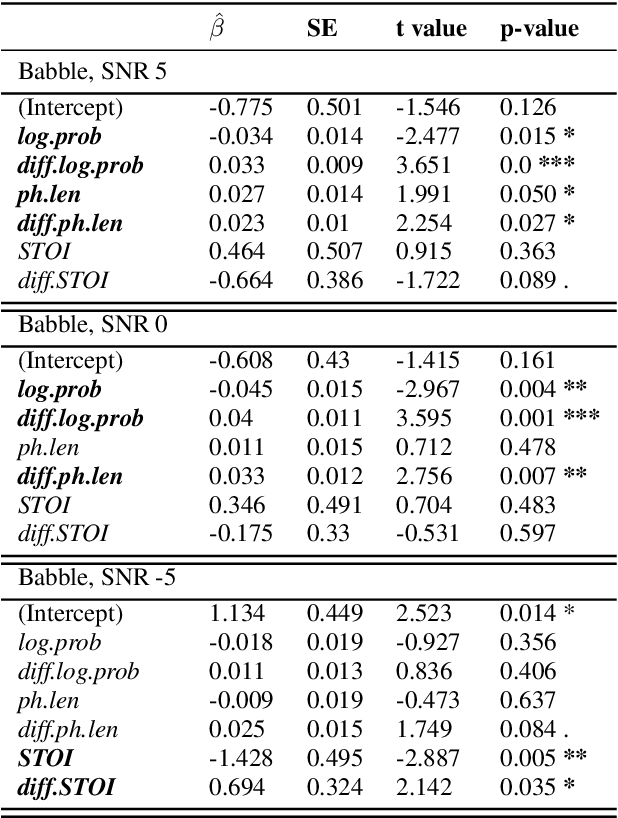
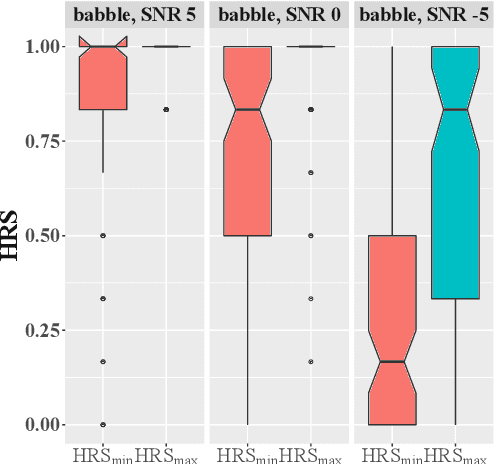
Listening in noisy environments can be difficult even for individuals with a normal hearing thresholds. The speech signal can be masked by noise, which may lead to word misperceptions on the side of the listener, and overall difficulty to understand the message. To mitigate hearing difficulties on listeners, a co-operative speaker utilizes voice modulation strategies like Lombard speech to generate noise-robust utterances, and similar solutions have been developed for speech synthesis systems. In this work, we propose an alternate solution of choosing noise-robust lexical paraphrases to represent an intended meaning. Our results show that lexical paraphrases differ in their intelligibility in noise. We evaluate the intelligibility of synonyms in context and find that choosing a lexical unit that is less risky to be misheard than its synonym introduced an average gain in comprehension of 37% at SNR -5 dB and 21% at SNR 0 dB for babble noise.