 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Spatial Distribution of Long-Term Trackers Scores
Aug 02, 2023



Long-Term tracking is a hot topic in Computer Vision. In this context, competitive models are presented every year, showing a constant growth rate in performances, mainly measured in standardized protocols as Visual Object Tracking (VOT) and Object Tracking Benchmark (OTB). Fusion-trackers strategy has been applied over last few years for overcoming the known re-detection problem, turning out to be an important breakthrough. Following this approach, this work aims to generalize the fusion concept to an arbitrary number of trackers used as baseline trackers in the pipeline, leveraging a learning phase to better understand how outcomes correlate with each other, even when no target is present. A model and data independence conjecture will be evidenced in the manuscript, yielding a recall of 0.738 on LTB-50 dataset when learning from VOT-LT2022, and 0.619 by reversing the two datasets. In both cases, results are strongly competitive with state-of-the-art and recall turns out to be the first on the podium.
A Hybrid Approach To Real-Time Multi-Object Tracking
Aug 02, 2023Multi-Object Tracking, also known as Multi-Target Tracking, is a significant area of computer vision that has many uses in a variety of settings. The development of deep learning, which has encouraged researchers to propose more and more work in this direction, has significantly impacted the scientific advancement around the study of tracking as well as many other domains related to computer vision. In fact, all of the solutions that are currently state-of-the-art in the literature and in the tracking industry, are built on top of deep learning methodologies that produce exceptionally good results. Deep learning is enabled thanks to the ever more powerful technology researchers can use to handle the significant computational resources demanded by these models. However, when real-time is a main requirement, developing a tracking system without being constrained by expensive hardware support with enormous computational resources is necessary to widen tracking applications in real-world contexts. To this end, a compromise is to combine powerful deep strategies with more traditional approaches to favor considerably lower processing solutions at the cost of less accurate tracking results even though suitable for real-time domains. Indeed, the present work goes in that direction, proposing a hybrid strategy for real-time multi-target tracking that combines effectively a classical optical flow algorithm with a deep learning architecture, targeted to a human-crowd tracking system exhibiting a desirable trade-off between performance in tracking precision and computational costs. The developed architecture was experimented with different settings, and yielded a MOTA of 0.608 out of the compared state-of-the-art 0.549 results, and about half the running time when introducing the optical flow phase, achieving almost the same performance in terms of accuracy.
Hypergraph Convolutional Networks for Weakly-Supervised Semantic Segmentation
Oct 11, 2022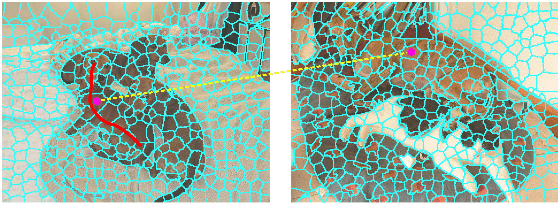

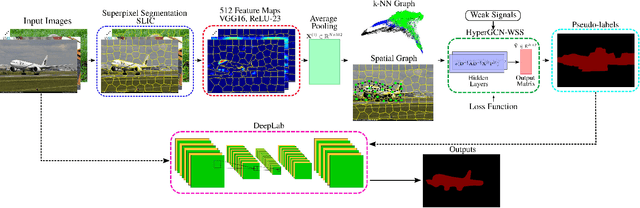
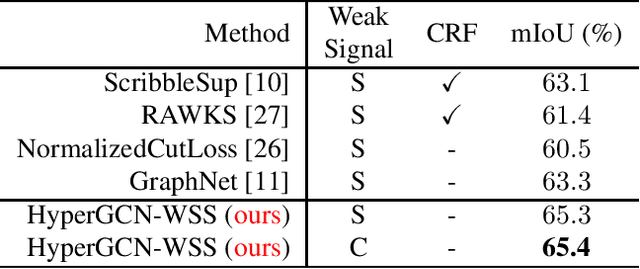
Semantic segmentation is a fundamental topic in computer vision. Several deep learning methods have been proposed for semantic segmentation with outstanding results. However, these models require a lot of densely annotated images. To address this problem, we propose a new algorithm that uses HyperGraph Convolutional Networks for Weakly-supervised Semantic Segmentation (HyperGCN-WSS). Our algorithm constructs spatial and k-Nearest Neighbor (k-NN) graphs from the images in the dataset to generate the hypergraphs. Then, we train a specialized HyperGraph Convolutional Network (HyperGCN) architecture using some weak signals. The outputs of the HyperGCN are denominated pseudo-labels, which are later used to train a DeepLab model for semantic segmentation. HyperGCN-WSS is evaluated on the PASCAL VOC 2012 dataset for semantic segmentation, using scribbles or clicks as weak signals. Our algorithm shows competitive performance against previous methods.