 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Deep Stereo (PDS): Toward applications-friendly deep stereo matching
Jun 05, 2018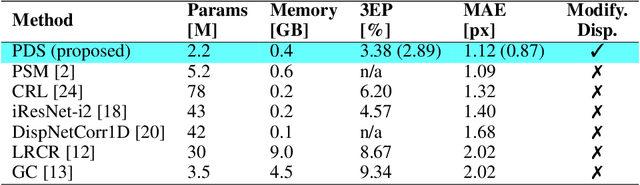



End-to-end deep-learning networks recently demonstrated extremely good perfor- mance for stereo matching. However, existing networks are difficult to use for practical applications since (1) they are memory-hungry and unable to process even modest-size images, (2) they have to be trained for a given disparity range. The Practical Deep Stereo (PDS) network that we propose addresses both issues: First, its architecture relies on novel bottleneck modules that drastically reduce the memory footprint in inference, and additional design choices allow to handle greater image size during training. This results in a model that leverages large image context to resolve matching ambiguities. Second, a novel sub-pixel cross- entropy loss combined with a MAP estimator make this network less sensitive to ambiguous matches, and applicable to any disparity range without re-training. We compare PDS to state-of-the-art methods published over the recent months, and demonstrate its superior performance on FlyingThings3D and KITTI sets.
Geometric calibration of Colour and Stereo Surface Imaging System of ESA's Trace Gas Orbiter
Jul 03, 2017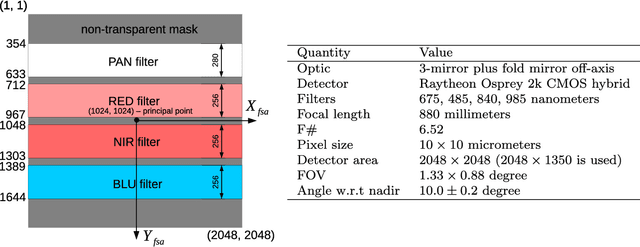
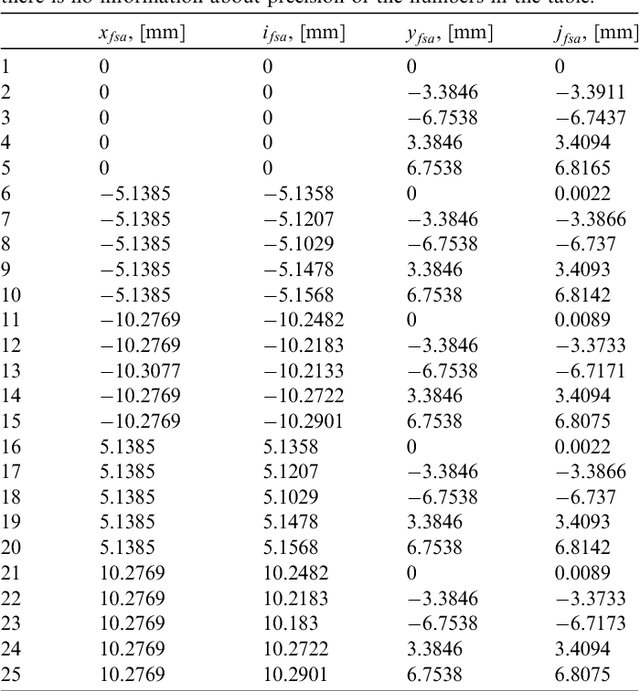
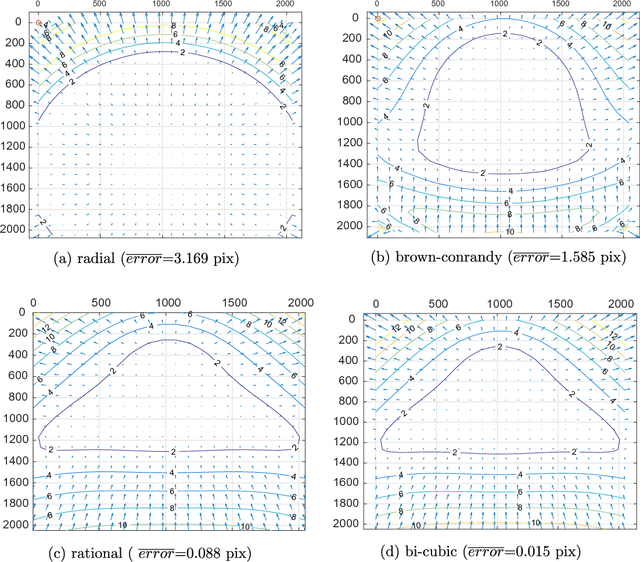

There are many geometric calibration methods for "standard" cameras. These methods, however, cannot be used for the calibration of telescopes with large focal lengths and complex off-axis optics. Moreover, specialized calibration methods for the telescopes are scarce in literature. We describe the calibration method that we developed for the Colour and Stereo Surface Imaging System (CaSSIS) telescope, on board of the ExoMars Trace Gas Orbiter (TGO). Although our method is described in the context of CaSSIS, with camera-specific experiments, it is general and can be applied to other telescopes. We further encourage re-use of the proposed method by making our calibration code and data available on-line.
Semi-supervised learning of deep metrics for stereo reconstruction
Dec 03, 2016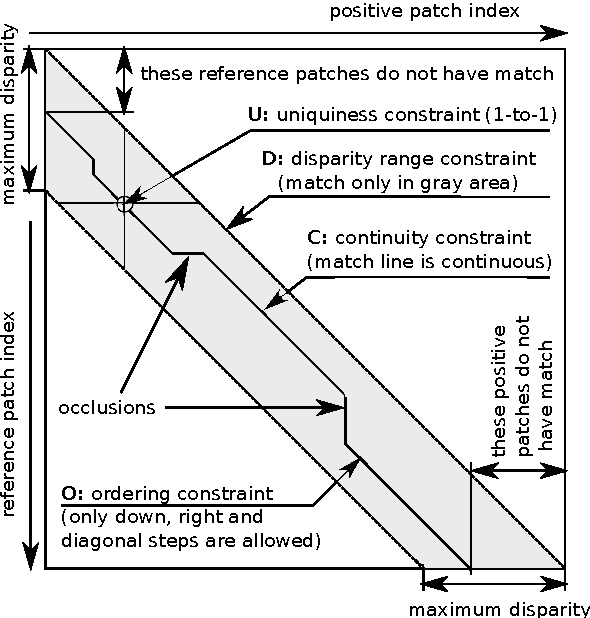

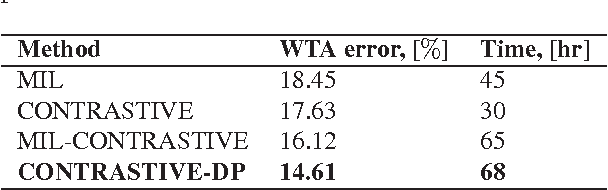

Deep-learning metrics have recently demonstrated extremely good performance to match image patches for stereo reconstruction. However, training such metrics requires large amount of labeled stereo images, which can be difficult or costly to collect for certain applications. The main contribution of our work is a new semi-supervised method for learning deep metrics from unlabeled stereo images, given coarse information about the scenes and the optical system. Our method alternatively optimizes the metric with a standard stochastic gradient descent, and applies stereo constraints to regularize its prediction. Experiments on reference data-sets show that, for a given network architecture, training with this new method without ground-truth produces a metric with performance as good as state-of-the-art baselines trained with the said ground-truth. This work has three practical implications. Firstly, it helps to overcome limitations of training sets, in particular noisy ground truth. Secondly it allows to use much more training data during learning. Thirdly, it allows to tune deep metric for a particular stereo system, even if ground truth is not available.