 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised learning of deep metrics for stereo reconstruction
Paper and Code
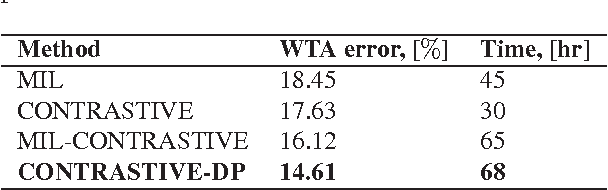
Dec 03, 2016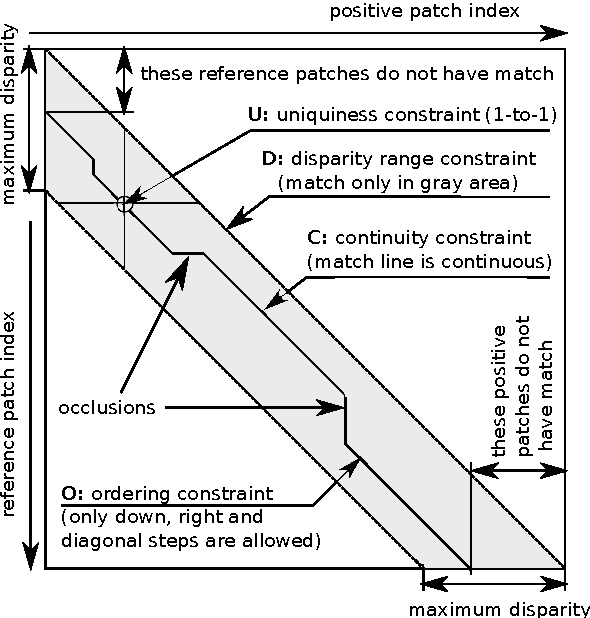


Deep-learning metrics have recently demonstrated extremely good performance to match image patches for stereo reconstruction. However, training such metrics requires large amount of labeled stereo images, which can be difficult or costly to collect for certain applications. The main contribution of our work is a new semi-supervised method for learning deep metrics from unlabeled stereo images, given coarse information about the scenes and the optical system. Our method alternatively optimizes the metric with a standard stochastic gradient descent, and applies stereo constraints to regularize its prediction. Experiments on reference data-sets show that, for a given network architecture, training with this new method without ground-truth produces a metric with performance as good as state-of-the-art baselines trained with the said ground-truth. This work has three practical implications. Firstly, it helps to overcome limitations of training sets, in particular noisy ground truth. Secondly it allows to use much more training data during learning. Thirdly, it allows to tune deep metric for a particular stereo system, even if ground truth is not available.