 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-Driven Crystal System Prediction for Perovskites Using Augmented X-ray Diffraction Data
Feb 04, 2026Prediction of crystal system from X-ray diffraction (XRD) spectra is a critical task in materials science, particularly for perovskite materials which are known for their diverse applications in photovoltaics, optoelectronics, and catalysis. In this study, we present a machine learning (ML)-driven framework that leverages advanced models, including Time Series Forest (TSF), Random Forest (RF), Extreme Gradient Boosting (XGBoost), Recurrent Neural Network (RNN), Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and a simple feedforward neural network (NN), to classify crystal systems, point groups, and space groups from XRD data of perovskite materials. To address class imbalance and enhance model robustness, we integrated feature augmentation strategies such as Synthetic Minority Over-sampling Technique (SMOTE), class weighting, jittering, and spectrum shifting, along with efficient data preprocessing pipelines. The TSF model with SMOTE augmentation achieved strong performance for crystal system prediction, with a Matthews correlation coefficient (MCC) of 0.9, an F1 score of 0.92, and an accuracy of 97.76%. For point and space group prediction, balanced accuracies above 95% were obtained. The model demonstrated high performance for symmetry-distinct classes, including cubic crystal systems, point groups 3m and m-3m, and space groups Pnma and Pnnn. This work highlights the potential of ML for XRD-based structural characterization and accelerated discovery of perovskite materials
* 37 pages, 7 figures. Author accepted manuscript. Published in Engineering Applications of Artificial Intelligence
From Image Collections to Point Clouds with Self-supervised Shape and Pose Networks
May 05, 2020
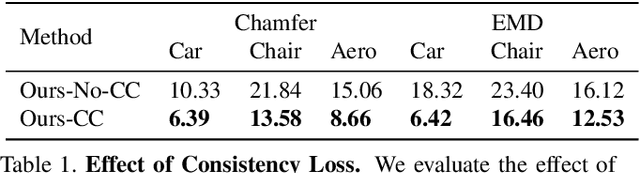
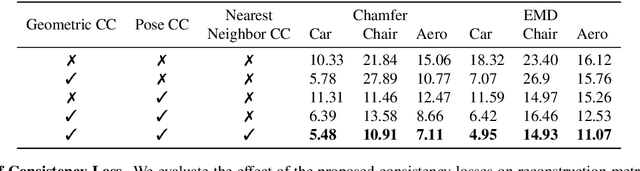

Reconstructing 3D models from 2D images is one of the fundamental problems in computer vision. In this work, we propose a deep learning technique for 3D object reconstruction from a single image. Contrary to recent works that either use 3D supervision or multi-view supervision, we use only single view images with no pose information during training as well. This makes our approach more practical requiring only an image collection of an object category and the corresponding silhouettes. We learn both 3D point cloud reconstruction and pose estimation networks in a self-supervised manner, making use of differentiable point cloud renderer to train with 2D supervision. A key novelty of the proposed technique is to impose 3D geometric reasoning into predicted 3D point clouds by rotating them with randomly sampled poses and then enforcing cycle consistency on both 3D reconstructions and poses. In addition, using single-view supervision allows us to do test-time optimization on a given test image. Experiments on the synthetic ShapeNet and real-world Pix3D datasets demonstrate that our approach, despite using less supervision, can achieve competitive performance compared to pose-supervised and multi-view supervised approaches.