 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Image Collections to Point Clouds with Self-supervised Shape and Pose Networks
Paper and Code

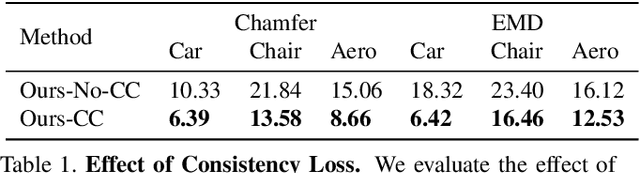
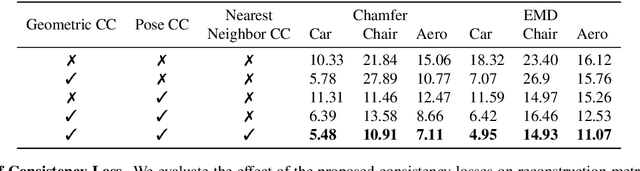

Reconstructing 3D models from 2D images is one of the fundamental problems in computer vision. In this work, we propose a deep learning technique for 3D object reconstruction from a single image. Contrary to recent works that either use 3D supervision or multi-view supervision, we use only single view images with no pose information during training as well. This makes our approach more practical requiring only an image collection of an object category and the corresponding silhouettes. We learn both 3D point cloud reconstruction and pose estimation networks in a self-supervised manner, making use of differentiable point cloud renderer to train with 2D supervision. A key novelty of the proposed technique is to impose 3D geometric reasoning into predicted 3D point clouds by rotating them with randomly sampled poses and then enforcing cycle consistency on both 3D reconstructions and poses. In addition, using single-view supervision allows us to do test-time optimization on a given test image. Experiments on the synthetic ShapeNet and real-world Pix3D datasets demonstrate that our approach, despite using less supervision, can achieve competitive performance compared to pose-supervised and multi-view supervised approaches.