 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Low-Dimensional Sensing Mapless Navigation of Terrestrial Mobile Robots Using Double Deep Reinforcement Learning Techniques
Oct 20, 2023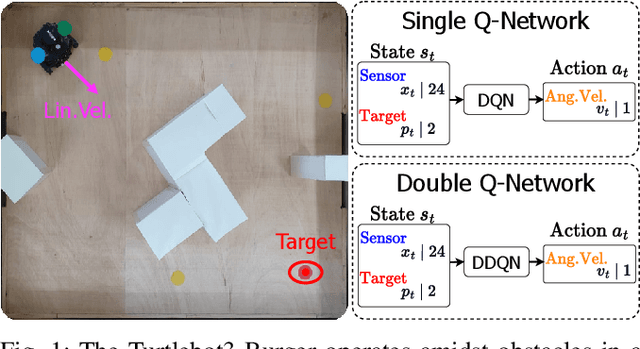

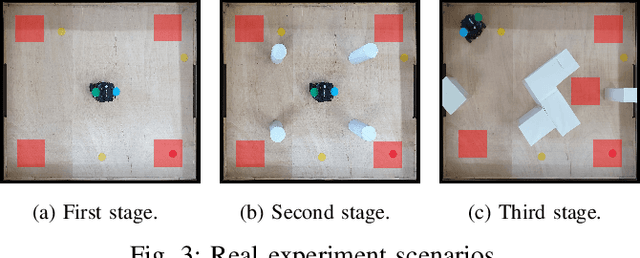

In this study, we present two distinct approaches within the realm of Deep Reinforcement Learning (Deep-RL) aimed at enhancing mapless navigation for a ground-based mobile robot. The research methodology primarily involves a comparative analysis between a Deep-RL strategy grounded in the foundational Deep Q-Network (DQN) algorithm, and an alternative approach based on the Double Deep Q-Network (DDQN) algorithm. The agents in these approaches leverage 24 measurements from laser range sampling, coupled with the agent's positional differentials and orientation relative to the target. This amalgamation of data influences the agents' determinations regarding navigation, ultimately dictating the robot's velocities. By embracing this parsimonious sensory framework as proposed, we successfully showcase the training of an agent for proficiently executing navigation tasks and adeptly circumventing obstacles. Notably, this accomplishment is attained without a dependency on intricate sensory inputs like those inherent to image-centric methodologies. The proposed methodology is evaluated in three different real environments, revealing that Double Deep structures significantly enhance the navigation capabilities of mobile robots compared to simple Q structures.