 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Assisted Content Analysis: Using Large Language Models to Support Deductive Coding
Jun 23, 2023



Deductive coding is a widely used qualitative research method for determining the prevalence of themes across documents. While useful, deductive coding is often burdensome and time consuming since it requires researchers to read, interpret, and reliably categorize a large body of unstructured text documents. Large language models (LLMs), like ChatGPT, are a class of quickly evolving AI tools that can perform a range of natural language processing and reasoning tasks. In this study, we explore the use of LLMs to reduce the time it takes for deductive coding while retaining the flexibility of a traditional content analysis. We outline the proposed approach, called LLM-assisted content analysis (LACA), along with an in-depth case study using GPT-3.5 for LACA on a publicly available deductive coding data set. Additionally, we conduct an empirical benchmark using LACA on 4 publicly available data sets to assess the broader question of how well GPT-3.5 performs across a range of deductive coding tasks. Overall, we find that GPT-3.5 can often perform deductive coding at levels of agreement comparable to human coders. Additionally, we demonstrate that LACA can help refine prompts for deductive coding, identify codes for which an LLM is randomly guessing, and help assess when to use LLMs vs. human coders for deductive coding. We conclude with several implications for future practice of deductive coding and related research methods.
Supervised Opinion Aspect Extraction by Exploiting Past Extraction Results
Dec 23, 2016
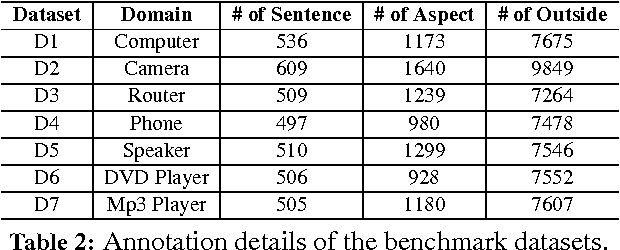
One of the key tasks of sentiment analysis of product reviews is to extract product aspects or features that users have expressed opinions on. In this work, we focus on using supervised sequence labeling as the base approach to performing the task. Although several extraction methods using sequence labeling methods such as Conditional Random Fields (CRF) and Hidden Markov Models (HMM) have been proposed, we show that this supervised approach can be significantly improved by exploiting the idea of concept sharing across multiple domains. For example, "screen" is an aspect in iPhone, but not only iPhone has a screen, many electronic devices have screens too. When "screen" appears in a review of a new domain (or product), it is likely to be an aspect too. Knowing this information enables us to do much better extraction in the new domain. This paper proposes a novel extraction method exploiting this idea in the context of supervised sequence labeling. Experimental results show that it produces markedly better results than without using the past information.