 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Algorithms for the Loop Cutset Problem
Aug 07, 2014
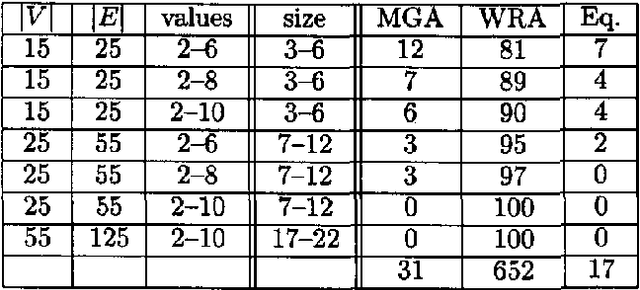
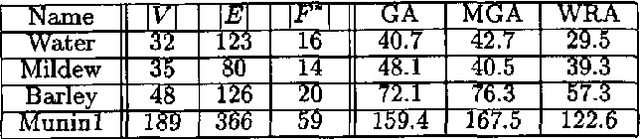
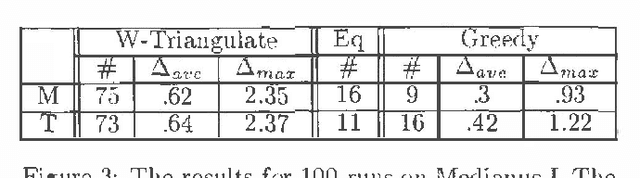
We show how to find a minimum loop cutset in a Bayesian network with high probability. Finding such a loop cutset is the first step in Pearl's method of conditioning for inference. Our random algorithm for finding a loop cutset, called "Repeated WGuessI", outputs a minimum loop cutset, after O(c 6^k k n) steps, with probability at least 1-(1 over{6^k})^{c 6^k}), where c>1 is a constant specified by the user, k is the size of a minimum weight loop cutset, and n is the number of vertices. We also show empirically that a variant of this algorithm, called WRA, often finds a loop cutset that is closer to the minimum loop cutset than the ones found by the best deterministic algorithms known.
Approximation Algorithms for the Loop Cutset Problem
Feb 27, 2013We show how to find a small loop curser in a Bayesian network. Finding such a loop cutset is the first step in the method of conditioning for inference. Our algorithm for finding a loop cutset, called MGA, finds a loop cutset which is guaranteed in the worst case to contain less than twice the number of variables contained in a minimum loop cutset. We test MGA on randomly generated graphs and find that the average ratio between the number of instances associated with the algorithms' output and the number of instances associated with a minimum solution is 1.22.
A Sufficiently Fast Algorithm for Finding Close to Optimal Junction Trees
Feb 13, 2013
An algorithm is developed for finding a close to optimal junction tree of a given graph G. The algorithm has a worst case complexity O(c^k n^a) where a and c are constants, n is the number of vertices, and k is the size of the largest clique in a junction tree of G in which this size is minimized. The algorithm guarantees that the logarithm of the size of the state space of the heaviest clique in the junction tree produced is less than a constant factor off the optimal value. When k = O(log n), our algorithm yields a polynomial inference algorithm for Bayesian networks.
Perfect Tree-Like Markovian Distributions
Jan 16, 2013We show that if a strictly positive joint probability distribution for a set of binary random variables factors according to a tree, then vertex separation represents all and only the independence relations enclosed in the distribution. The same result is shown to hold also for multivariate strictly positive normal distributions. Our proof uses a new property of conditional independence that holds for these two classes of probability distributions.