 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Methodology for Thermal Limit Bias Predictability Through Artificial Intelligence
Mar 15, 2026Nuclear power plant operators face significant challenges due to unpredictable deviations between offline and online thermal limits, a phenomenon known as thermal limit bias, which leads to conservative design margins, increased fuel costs, and operational inefficiencies. This work presents a deep learning based methodology to predict and correct this bias for Boiling Water Reactors (BWRs), focusing on the Maximum Fraction of Limiting Power Density (MFLPD) metric used to track the Linear Heat Generation Rate (LHGR) limit. The proposed model employs a fully convolutional encoder decoder architecture, incorporating a feature fusion network to predict corrected MFLPD values closer to online measurements. Evaluated across five independent fuel cycles, the model reduces the mean nodal array error by 74 percent, the mean absolute deviation in limiting values by 72 percent, and the maximum bias by 52 percent compared to offline methods. These results demonstrate the model's potential to meaningfully improve fuel cycle economics and operational planning, and a commercial variant has been deployed at multiple operating BWRs.
Optimization through In-Context Learning and Iterative LLM Prompting for Nuclear Engineering Design Problems
Mar 25, 2025

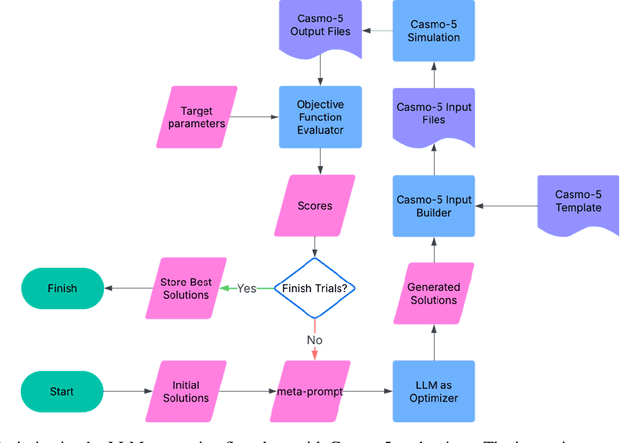

The optimization of nuclear engineering designs, such as nuclear fuel assembly configurations, involves managing competing objectives like reactivity control and power distribution. This study explores the use of Optimization by Prompting, an iterative approach utilizing large language models (LLMs), to address these challenges. The method is straightforward to implement, requiring no hyperparameter tuning or complex mathematical formulations. Optimization problems can be described in plain English, with only an evaluator and a parsing script needed for execution. The in-context learning capabilities of LLMs enable them to understand problem nuances, therefore, they have the potential to surpass traditional metaheuristic optimization methods. This study demonstrates the application of LLMs as optimizers to Boiling Water Reactor (BWR) fuel lattice design, showing the capability of commercial LLMs to achieve superior optimization results compared to traditional methods.
Predicting BWR Criticality with Data-Driven Machine Learning Model
Nov 11, 2024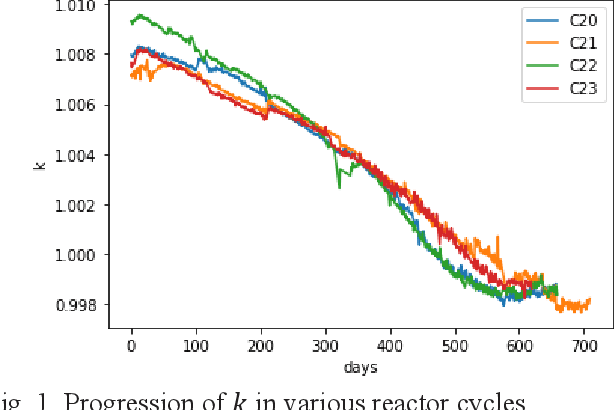
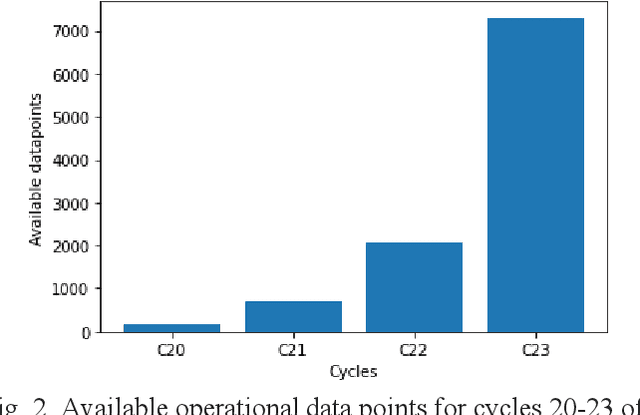
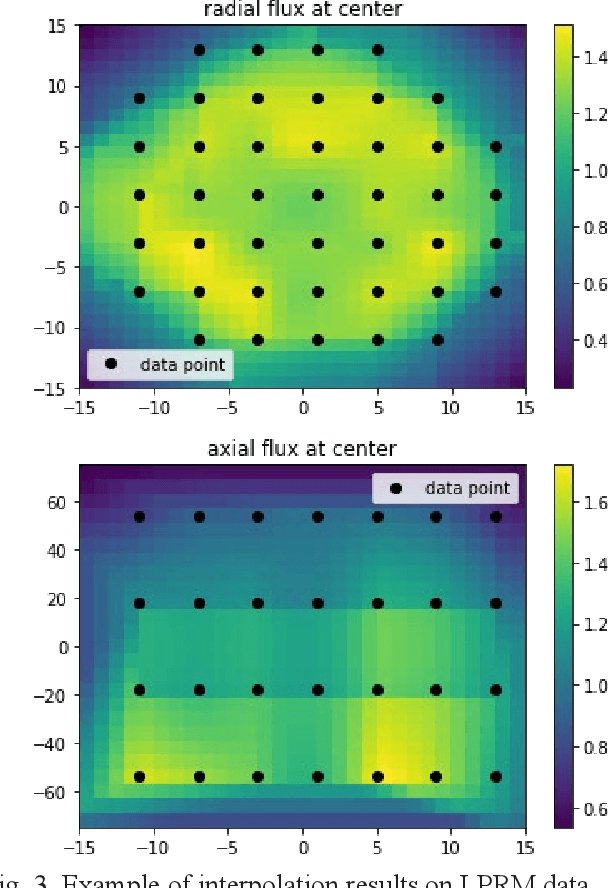
One of the challenges in operating nuclear power plants is to decide the amount of fuel needed in a cycle. Large-scale nuclear power plants are designed to operate at base load, meaning that they are expected to always operate at full power. Economically, a nuclear power plant should burn enough fuel to maintain criticality until the end of a cycle (EOC). If the reactor goes subcritical before the end of a cycle, it may result in early coastdown as the fuel in the core is already depleted. On contrary, if the reactor still has significant excess reactivity by the end of a cycle, the remaining fuels will remain unused. In both cases, the plant may lose a significant amount of money. This work proposes an innovative method based on a data-driven deep learning model to estimate the excess criticality of a boiling water reactor.
AI Enabled Neutron Flux Measurement and Virtual Calibration in Boiling Water Reactors
Sep 25, 2024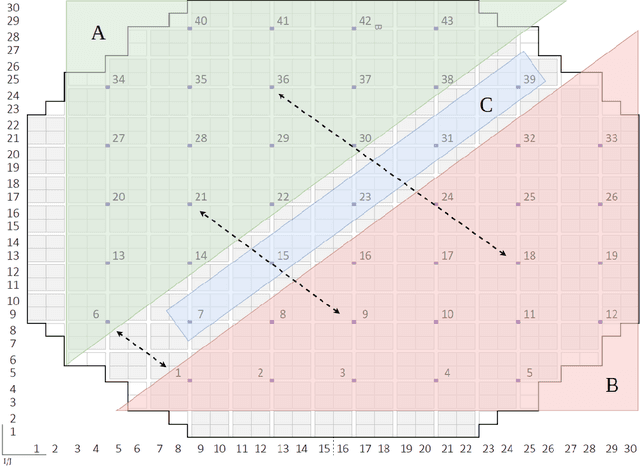
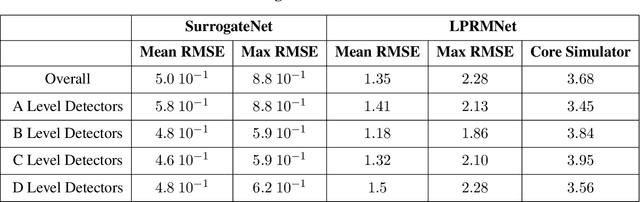
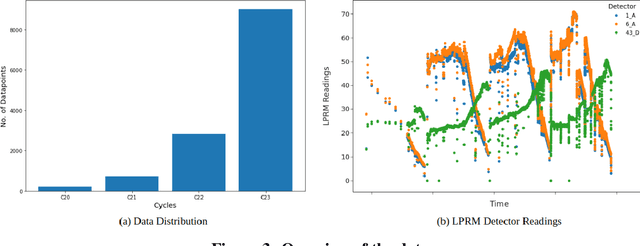
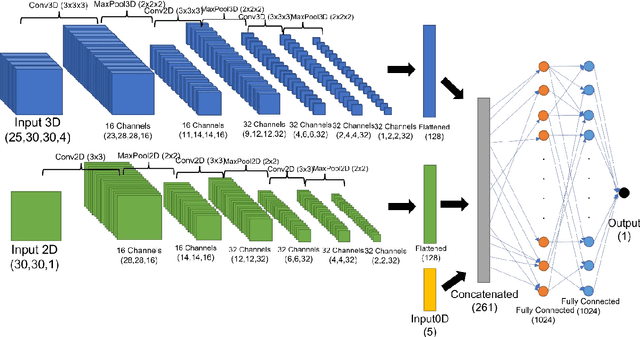
Accurately capturing the three dimensional power distribution within a reactor core is vital for ensuring the safe and economical operation of the reactor, compliance with Technical Specifications, and fuel cycle planning (safety, control, and performance evaluation). Offline (that is, during cycle planning and core design), a three dimensional neutronics simulator is used to estimate the reactor's power, moderator, void, and flow distributions, from which margin to thermal limits and fuel exposures can be approximated. Online, this is accomplished with a system of local power range monitors (LPRMs) designed to capture enough neutron flux information to infer the full nodal power distribution. Certain problems with this process, ranging from measurement and calibration to the power adaption process, pose challenges to operators and limit the ability to design reload cores economically (e.g., engineering in insufficient margin or more margin than required). Artificial intelligence (AI) and machine learning (ML) are being used to solve the problems to reduce maintenance costs, improve the accuracy of online local power measurements, and decrease the bias between offline and online power distributions, thereby leading to a greater ability to design safe and economical reload cores. We present ML models trained from two deep neural network (DNN) architectures, SurrogateNet and LPRMNet, that demonstrate a testing error of 1 percent and 3 percent, respectively. Applications of these models can include virtual sensing capability for bypassed or malfunctioning LPRMs, on demand virtual calibration of detectors between successive calibrations, highly accurate nuclear end of life determinations for LPRMs, and reduced bias between measured and predicted power distributions within the core.
Multi-Domain Few-Shot Learning and Dataset for Agricultural Applications
Sep 21, 2021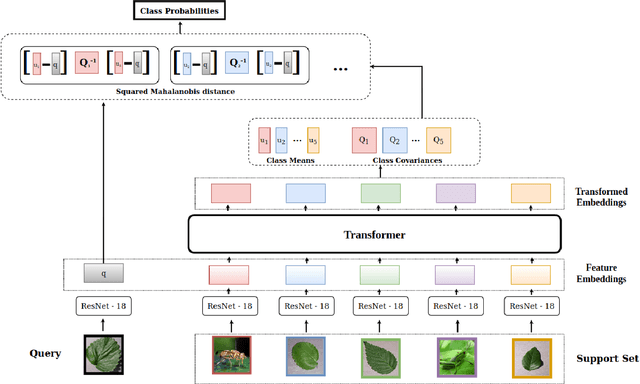
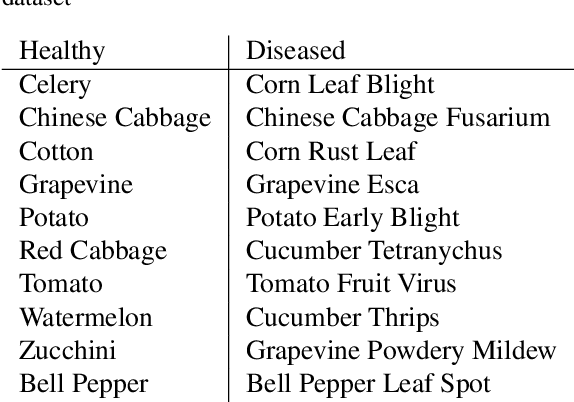

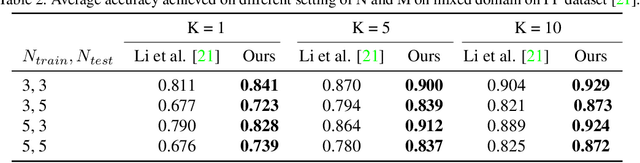
Automatic classification of pests and plants (both healthy and diseased) is of paramount importance in agriculture to improve yield. Conventional deep learning models based on convolutional neural networks require thousands of labeled examples per category. In this work we propose a method to learn from a few samples to automatically classify different pests, plants, and their diseases, using Few-Shot Learning (FSL). We learn a feature extractor to generate embeddings and then update the embeddings using Transformers. Using Mahalanobis distance, a class-covariance-based metric, we then calculate the similarity of the transformed embeddings with the embedding of the image to be classified. Using our proposed architecture, we conduct extensive experiments on multiple datasets showing the effectiveness of our proposed model. We conduct 42 experiments in total to comprehensively analyze the model and it achieves up to 14% and 24% performance gains on few-shot image classification benchmarks on two datasets. We also compile a new FSL dataset containing images of healthy and diseased plants taken in real-world settings. Using our proposed architecture which has been shown to outperform several existing FSL architectures in agriculture, we provide strong baselines on our newly proposed dataset.
Pose-based Sign Language Recognition using GCN and BERT
Dec 01, 2020
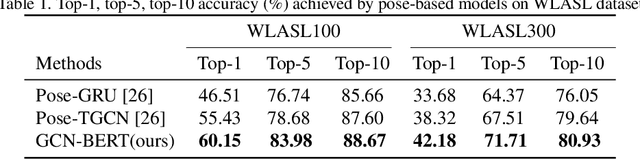
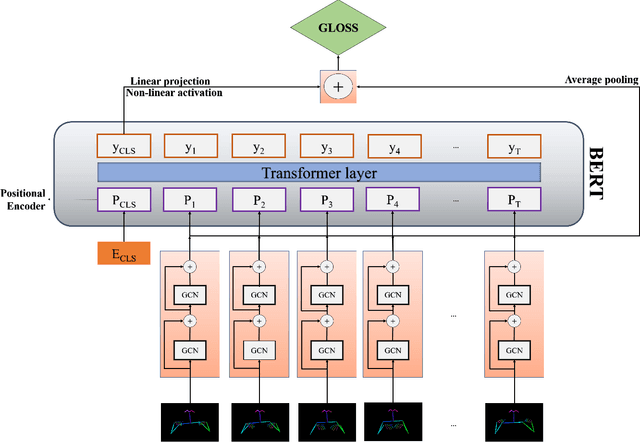

Sign language recognition (SLR) plays a crucial role in bridging the communication gap between the hearing and vocally impaired community and the rest of the society. Word-level sign language recognition (WSLR) is the first important step towards understanding and interpreting sign language. However, recognizing signs from videos is a challenging task as the meaning of a word depends on a combination of subtle body motions, hand configurations, and other movements. Recent pose-based architectures for WSLR either model both the spatial and temporal dependencies among the poses in different frames simultaneously or only model the temporal information without fully utilizing the spatial information. We tackle the problem of WSLR using a novel pose-based approach, which captures spatial and temporal information separately and performs late fusion. Our proposed architecture explicitly captures the spatial interactions in the video using a Graph Convolutional Network (GCN). The temporal dependencies between the frames are captured using Bidirectional Encoder Representations from Transformers (BERT). Experimental results on WLASL, a standard word-level sign language recognition dataset show that our model significantly outperforms the state-of-the-art on pose-based methods by achieving an improvement in the prediction accuracy by up to 5%.