Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Students on Sesame Street: What Order-Aware Matrix Embeddings Can Learn from BERT
Sep 17, 2021
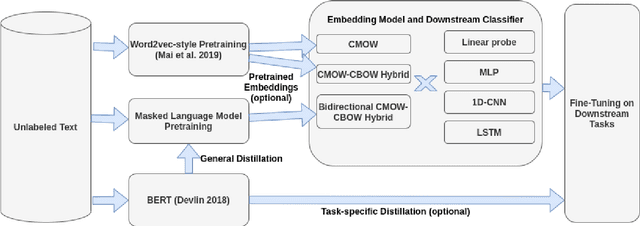
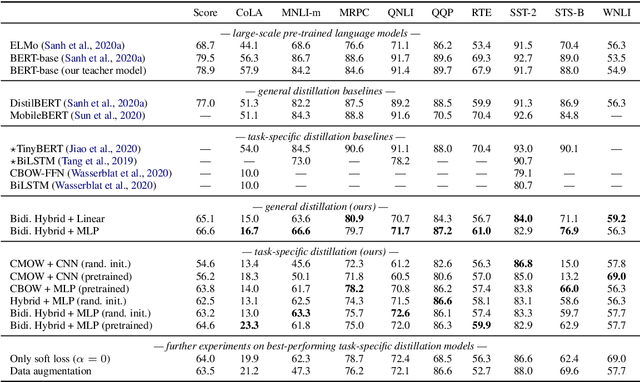

Large-scale pretrained language models (PreLMs) are revolutionizing natural language processing across all benchmarks. However, their sheer size is prohibitive in low-resource or large-scale applications. While common approaches reduce the size of PreLMs via same-architecture distillation or pruning, we explore distilling PreLMs into more efficient order-aware embedding models. Our results on the GLUE benchmark show that embedding-centric students, which have learned from BERT, yield scores comparable to DistilBERT on QQP and RTE, often match or exceed the scores of ELMo, and only fall behind on detecting linguistic acceptability.
* 10 pages + 6 pages supplementary material
Via