 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Assignment of Labels for Active Learning with Sparse and Noisy Annotations
Jul 25, 2023

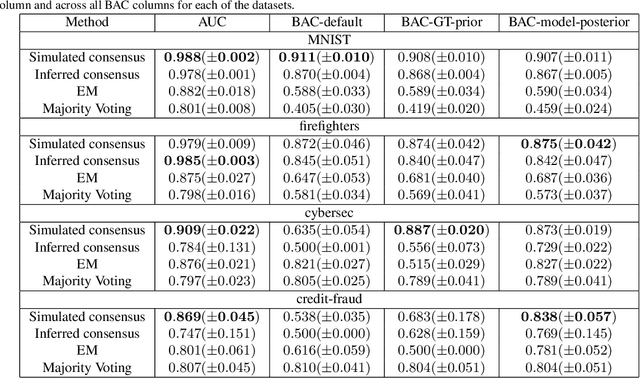

Supervised classification algorithms are used to solve a growing number of real-life problems around the globe. Their performance is strictly connected with the quality of labels used in training. Unfortunately, acquiring good-quality annotations for many tasks is infeasible or too expensive to be done in practice. To tackle this challenge, active learning algorithms are commonly employed to select only the most relevant data for labeling. However, this is possible only when the quality and quantity of labels acquired from experts are sufficient. Unfortunately, in many applications, a trade-off between annotating individual samples by multiple annotators to increase label quality vs. annotating new samples to increase the total number of labeled instances is necessary. In this paper, we address the issue of faulty data annotations in the context of active learning. In particular, we propose two novel annotation unification algorithms that utilize unlabeled parts of the sample space. The proposed methods require little to no intersection between samples annotated by different experts. Our experiments on four public datasets indicate the robustness and superiority of the proposed methods in both, the estimation of the annotator's reliability, and the assignment of actual labels, against the state-of-the-art algorithms and the simple majority voting.
Schema matching using Gaussian mixture models with Wasserstein distance
Nov 28, 2021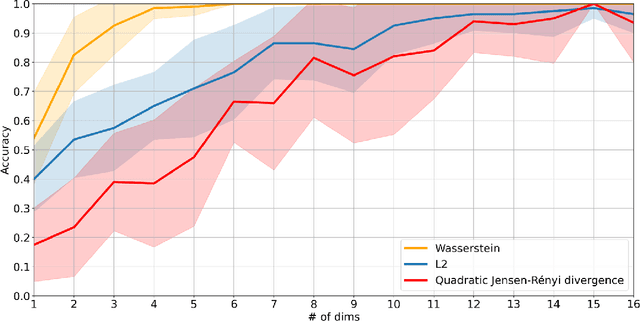
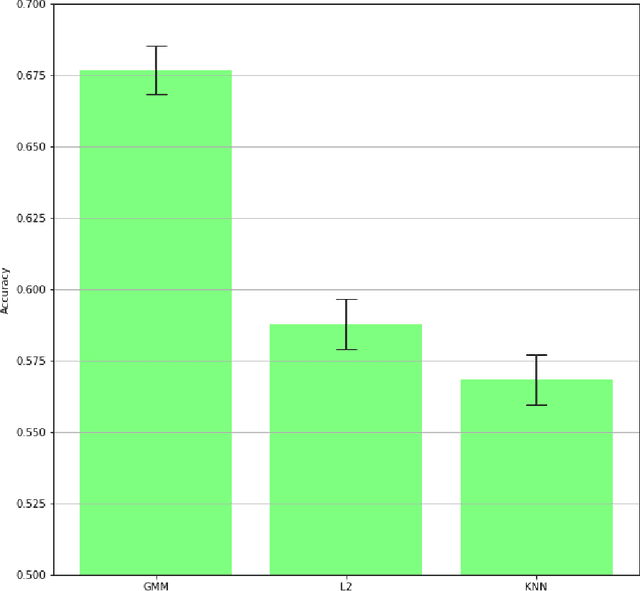
Gaussian mixture models find their place as a powerful tool, mostly in the clustering problem, but with proper preparation also in feature extraction, pattern recognition, image segmentation and in general machine learning. When faced with the problem of schema matching, different mixture models computed on different pieces of data can maintain crucial information about the structure of the dataset. In order to measure or compare results from mixture models, the Wasserstein distance can be very useful, however it is not easy to calculate for mixture distributions. In this paper we derive one of possible approximations for the Wasserstein distance between Gaussian mixture models and reduce it to linear problem. Furthermore, application examples concerning real world data are shown.
Improving Hearthstone AI by Combining MCTS and Supervised Learning Algorithms
Aug 14, 2018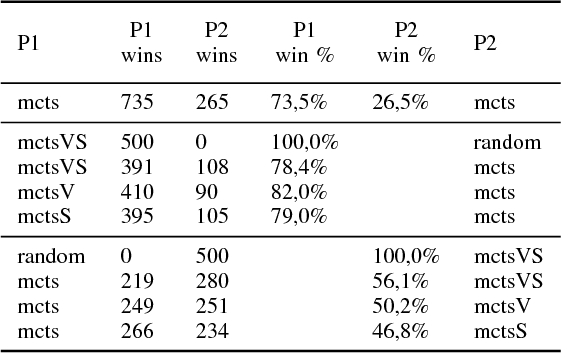
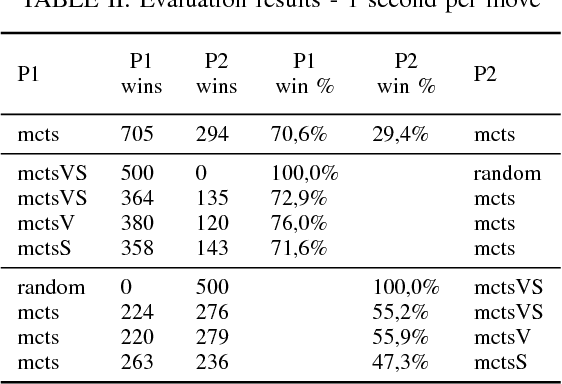
We investigate the impact of supervised prediction models on the strength and efficiency of artificial agents that use the Monte-Carlo Tree Search (MCTS) algorithm to play a popular video game Hearthstone: Heroes of Warcraft. We overview our custom implementation of the MCTS that is well-suited for games with partially hidden information and random effects. We also describe experiments which we designed to quantify the performance of our Hearthstone agent's decision making. We show that even simple neural networks can be trained and successfully used for the evaluation of game states. Moreover, we demonstrate that by providing a guidance to the game state search heuristic, it is possible to substantially improve the win rate, and at the same time reduce the required computations.
Helping AI to Play Hearthstone: AAIA'17 Data Mining Challenge
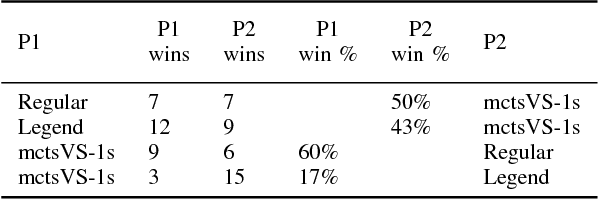
Aug 02, 2017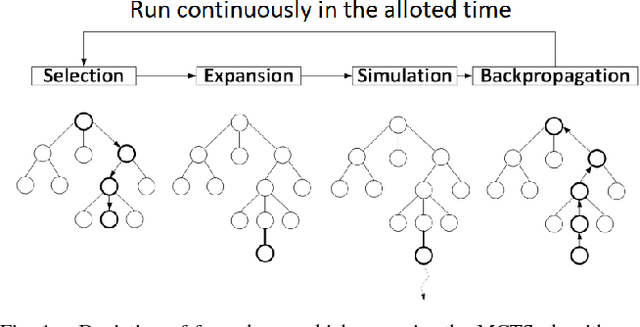
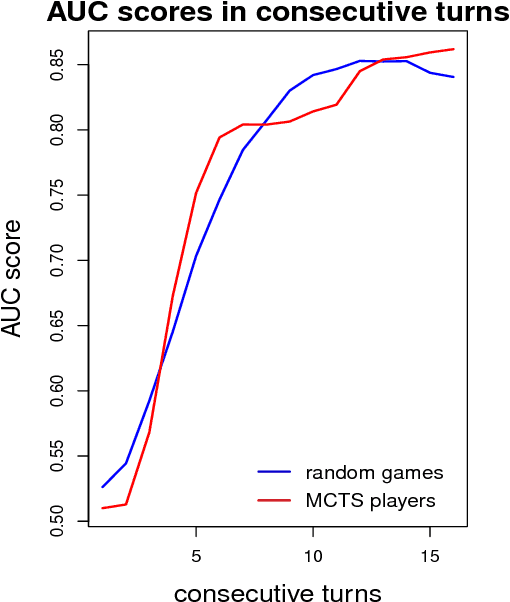
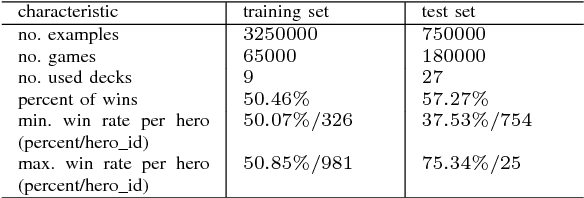
This paper summarizes the AAIA'17 Data Mining Challenge: Helping AI to Play Hearthstone which was held between March 23, and May 15, 2017 at the Knowledge Pit platform. We briefly describe the scope and background of this competition in the context of a more general project related to the development of an AI engine for video games, called Grail. We also discuss the outcomes of this challenge and demonstrate how predictive models for the assessment of player's winning chances can be utilized in a construction of an intelligent agent for playing Hearthstone. Finally, we show a few selected machine learning approaches for modeling state and action values in Hearthstone. We provide evaluation for a few promising solutions that may be used to create more advanced types of agents, especially in conjunction with Monte Carlo Tree Search algorithms.