 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Many Challenges of Human-Like Agents in Virtual Game Environments
May 26, 2025Human-like agents are an increasingly important topic in games and beyond. Believable non-player characters enhance the gaming experience by improving immersion and providing entertainment. They also offer players the opportunity to engage with AI entities that can function as opponents, teachers, or cooperating partners. Additionally, in games where bots are prohibited -- and even more so in non-game environments -- there is a need for methods capable of identifying whether digital interactions occur with bots or humans. This leads to two fundamental research questions: (1) how to model and implement human-like AI, and (2) how to measure its degree of human likeness. This article offers two contributions. The first one is a survey of the most significant challenges in implementing human-like AI in games (or any virtual environment featuring simulated agents, although this article specifically focuses on games). Thirteen such challenges, both conceptual and technical, are discussed in detail. The second is an empirical study performed in a tactical video game that addresses the research question: "Is it possible to distinguish human players from bots (AI agents) based on empirical data?" A machine-learning approach using a custom deep recurrent convolutional neural network is presented. We hypothesize that the more challenging it is to create human-like AI for a given game, the easier it becomes to develop a method for distinguishing humans from AI-driven players.
Robust Assignment of Labels for Active Learning with Sparse and Noisy Annotations
Jul 25, 2023

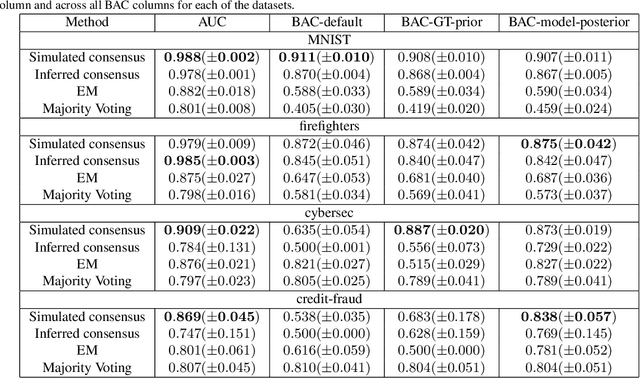

Supervised classification algorithms are used to solve a growing number of real-life problems around the globe. Their performance is strictly connected with the quality of labels used in training. Unfortunately, acquiring good-quality annotations for many tasks is infeasible or too expensive to be done in practice. To tackle this challenge, active learning algorithms are commonly employed to select only the most relevant data for labeling. However, this is possible only when the quality and quantity of labels acquired from experts are sufficient. Unfortunately, in many applications, a trade-off between annotating individual samples by multiple annotators to increase label quality vs. annotating new samples to increase the total number of labeled instances is necessary. In this paper, we address the issue of faulty data annotations in the context of active learning. In particular, we propose two novel annotation unification algorithms that utilize unlabeled parts of the sample space. The proposed methods require little to no intersection between samples annotated by different experts. Our experiments on four public datasets indicate the robustness and superiority of the proposed methods in both, the estimation of the annotator's reliability, and the assignment of actual labels, against the state-of-the-art algorithms and the simple majority voting.
Schema matching using Gaussian mixture models with Wasserstein distance
Nov 28, 2021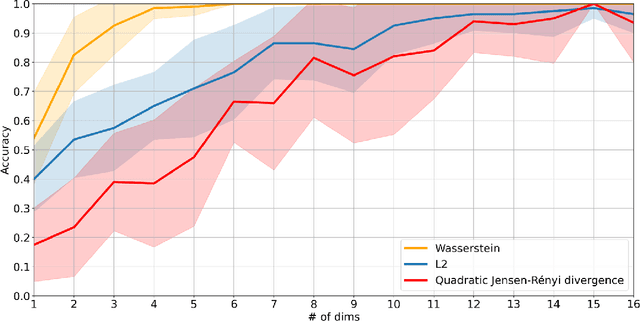
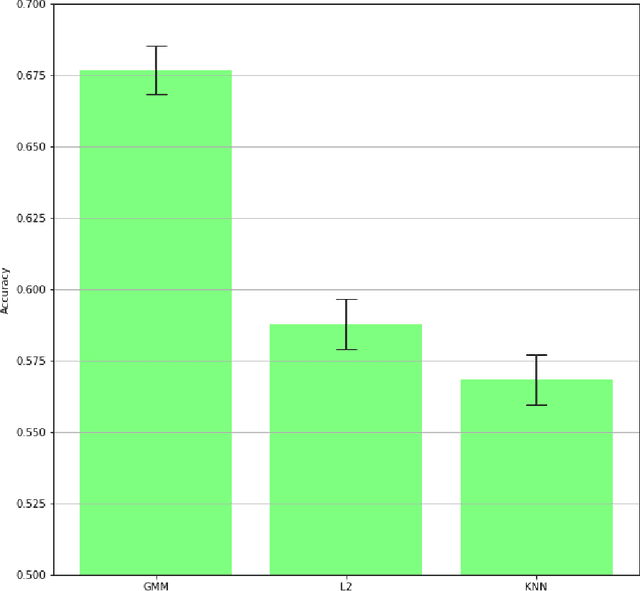
Gaussian mixture models find their place as a powerful tool, mostly in the clustering problem, but with proper preparation also in feature extraction, pattern recognition, image segmentation and in general machine learning. When faced with the problem of schema matching, different mixture models computed on different pieces of data can maintain crucial information about the structure of the dataset. In order to measure or compare results from mixture models, the Wasserstein distance can be very useful, however it is not easy to calculate for mixture distributions. In this paper we derive one of possible approximations for the Wasserstein distance between Gaussian mixture models and reduce it to linear problem. Furthermore, application examples concerning real world data are shown.