 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of AI on the Cyber Offense-Defense Balance and the Character of Cyber Conflict
Apr 17, 2025Unlike other domains of conflict, and unlike other fields with high anticipated risk from AI, the cyber domain is intrinsically digital with a tight feedback loop between AI training and cyber application. Cyber may have some of the largest and earliest impacts from AI, so it is important to understand how the cyber domain may change as AI continues to advance. Our approach reviewed the literature, collecting nine arguments that have been proposed for offensive advantage in cyber conflict and nine proposed arguments for defensive advantage. We include an additional forty-eight arguments that have been proposed to give cyber conflict and competition its character as collected separately by Healey, Jervis, and Nandrajog. We then consider how each of those arguments and propositions might change with varying degrees of AI advancement. We find that the cyber domain is too multifaceted for a single answer to whether AI will enhance offense or defense broadly. AI will improve some aspects, hinder others, and leave some aspects unchanged. We collect and present forty-four ways that we expect AI to impact the cyber offense-defense balance and the character of cyber conflict and competition.
Empirical Evaluation of Physical Adversarial Patch Attacks Against Overhead Object Detection Models
Jun 25, 2022



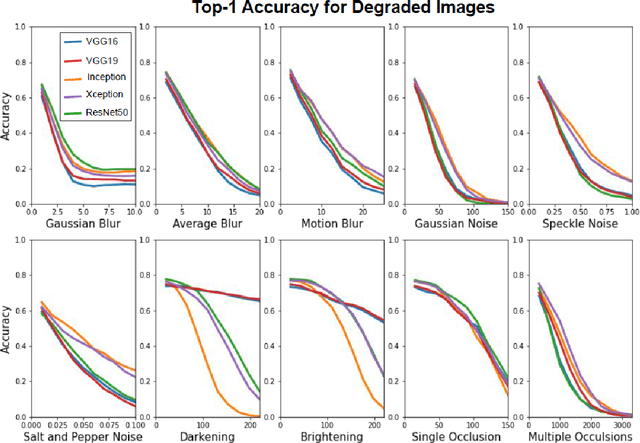
Adversarial patches are images designed to fool otherwise well-performing neural network-based computer vision models. Although these attacks were initially conceived of and studied digitally, in that the raw pixel values of the image were perturbed, recent work has demonstrated that these attacks can successfully transfer to the physical world. This can be accomplished by printing out the patch and adding it into scenes of newly captured images or video footage. In this work we further test the efficacy of adversarial patch attacks in the physical world under more challenging conditions. We consider object detection models trained on overhead imagery acquired through aerial or satellite cameras, and we test physical adversarial patches inserted into scenes of a desert environment. Our main finding is that it is far more difficult to successfully implement the adversarial patch attacks under these conditions than in the previously considered conditions. This has important implications for AI safety as the real-world threat posed by adversarial examples may be overstated.
Downscaling Attack and Defense: Turning What You See Back Into What You Get
Oct 07, 2020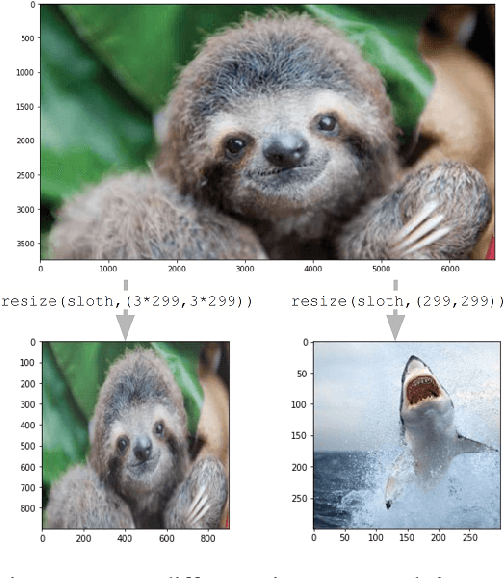
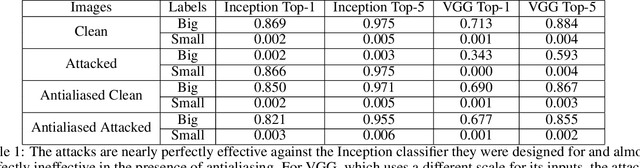
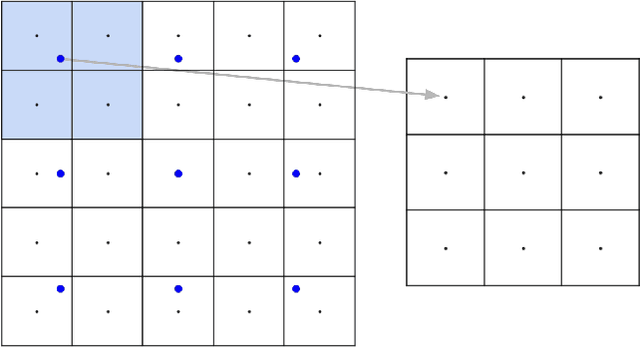
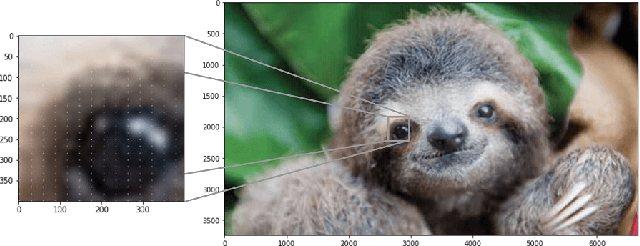
The resizing of images, which is typically a required part of preprocessing for computer vision systems, is vulnerable to attack. Images can be created such that the image is completely different at machine-vision scales than at other scales and the default settings for some common computer vision and machine learning systems are vulnerable. We show that defenses exist and are trivial to administer provided that defenders are aware of the threat. These attacks and defenses help to establish the role of input sanitization in machine learning.
Estimating the Brittleness of AI: Safety Integrity Levels and the Need for Testing Out-Of-Distribution Performance
Sep 02, 2020

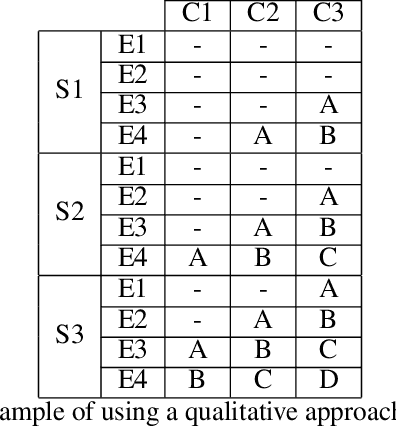
Test, Evaluation, Verification, and Validation (TEVV) for Artificial Intelligence (AI) is a challenge that threatens to limit the economic and societal rewards that AI researchers have devoted themselves to producing. A central task of TEVV for AI is estimating brittleness, where brittleness implies that the system functions well within some bounds and poorly outside of those bounds. This paper argues that neither of those criteria are certain of Deep Neural Networks. First, highly touted AI successes (eg. image classification and speech recognition) are orders of magnitude more failure-prone than are typically certified in critical systems even within design bounds (perfectly in-distribution sampling). Second, performance falls off only gradually as inputs become further Out-Of-Distribution (OOD). Enhanced emphasis is needed on designing systems that are resilient despite failure-prone AI components as well as on evaluating and improving OOD performance in order to get AI to where it can clear the challenging hurdles of TEVV and certification.
Adversarial Examples for Cost-Sensitive Classifiers
Oct 04, 2019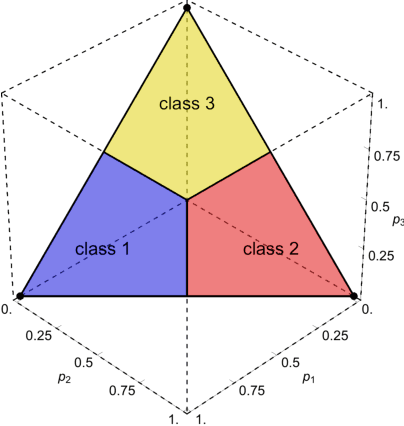
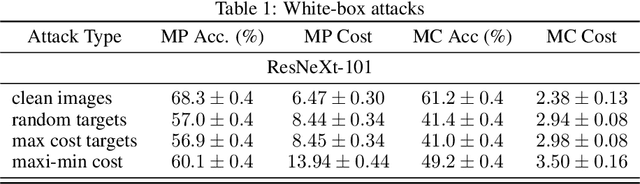
Motivated by safety-critical classification problems, we investigate adversarial attacks against cost-sensitive classifiers. We use current state-of-the-art adversarially-resistant neural network classifiers [1] as the underlying models. Cost-sensitive predictions are then achieved via a final processing step in the feed-forward evaluation of the network. We evaluate the effectiveness of cost-sensitive classifiers against a variety of attacks and we introduce a new cost-sensitive attack which performs better than targeted attacks in some cases. We also explored the measures a defender can take in order to limit their vulnerability to these attacks. This attacker/defender scenario is naturally framed as a two-player zero-sum finite game which we analyze using game theory.