 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Must Have Clicked on this Ad by Mistake! Data-Driven Identification of Accidental Clicks on Mobile Ads with Applications to Advertiser Cost Discounting and Click-Through Rate Prediction
Apr 03, 2018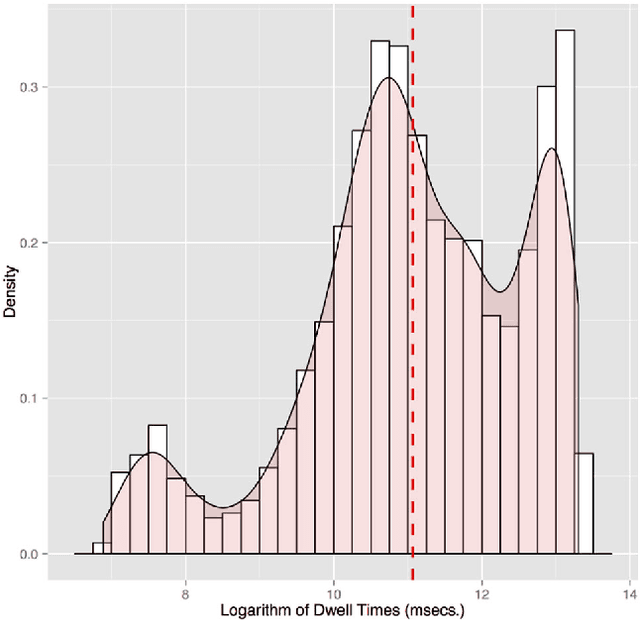


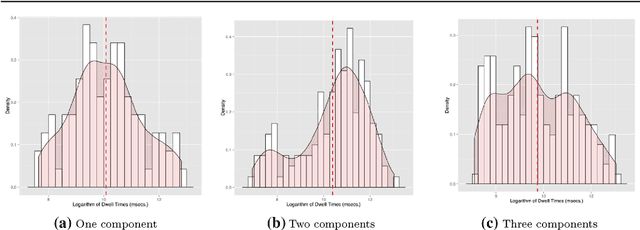
In the cost per click (CPC) pricing model, an advertiser pays an ad network only when a user clicks on an ad; in turn, the ad network gives a share of that revenue to the publisher where the ad was impressed. Still, advertisers may be unsatisfied with ad networks charging them for "valueless" clicks, or so-called accidental clicks. [...] Charging advertisers for such clicks is detrimental in the long term as the advertiser may decide to run their campaigns on other ad networks. In addition, machine-learned click models trained to predict which ad will bring the highest revenue may overestimate an ad click-through rate, and as a consequence negatively impacting revenue for both the ad network and the publisher. In this work, we propose a data-driven method to detect accidental clicks from the perspective of the ad network. We collect observations of time spent by users on a large set of ad landing pages - i.e., dwell time. We notice that the majority of per-ad distributions of dwell time fit to a mixture of distributions, where each component may correspond to a particular type of clicks, the first one being accidental. We then estimate dwell time thresholds of accidental clicks from that component. Using our method to identify accidental clicks, we then propose a technique that smoothly discounts the advertiser's cost of accidental clicks at billing time. Experiments conducted on a large dataset of ads served on Yahoo mobile apps confirm that our thresholds are stable over time, and revenue loss in the short term is marginal. We also compare the performance of an existing machine-learned click model trained on all ad clicks with that of the same model trained only on non-accidental clicks. There, we observe an increase in both ad click-through rate (+3.9%) and revenue (+0.2%) on ads served by the Yahoo Gemini network when using the latter. [...]
Interpretable Predictions of Tree-based Ensembles via Actionable Feature Tweaking
Jun 20, 2017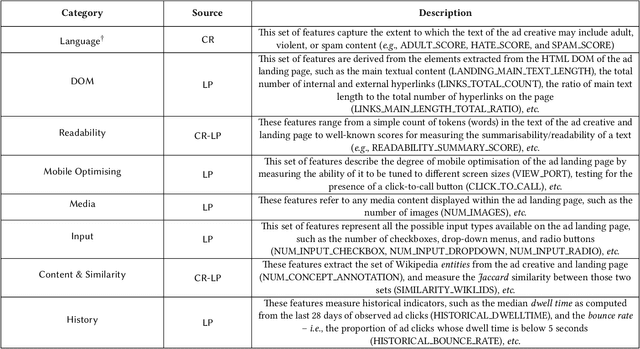
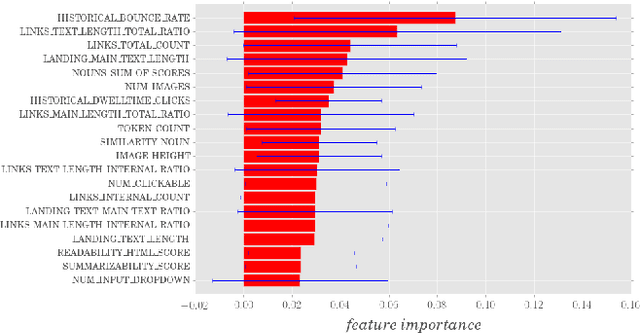

Machine-learned models are often described as "black boxes". In many real-world applications however, models may have to sacrifice predictive power in favour of human-interpretability. When this is the case, feature engineering becomes a crucial task, which requires significant and time-consuming human effort. Whilst some features are inherently static, representing properties that cannot be influenced (e.g., the age of an individual), others capture characteristics that could be adjusted (e.g., the daily amount of carbohydrates taken). Nonetheless, once a model is learned from the data, each prediction it makes on new instances is irreversible - assuming every instance to be a static point located in the chosen feature space. There are many circumstances however where it is important to understand (i) why a model outputs a certain prediction on a given instance, (ii) which adjustable features of that instance should be modified, and finally (iii) how to alter such a prediction when the mutated instance is input back to the model. In this paper, we present a technique that exploits the internals of a tree-based ensemble classifier to offer recommendations for transforming true negative instances into positively predicted ones. We demonstrate the validity of our approach using an online advertising application. First, we design a Random Forest classifier that effectively separates between two types of ads: low (negative) and high (positive) quality ads (instances). Then, we introduce an algorithm that provides recommendations that aim to transform a low quality ad (negative instance) into a high quality one (positive instance). Finally, we evaluate our approach on a subset of the active inventory of a large ad network, Yahoo Gemini.